
更多精彩内容,欢迎关注公众号:数量技术宅。想要获取本期分享的完整策略代码,请加技术宅微信:sljsz01
我们先来回顾一下,一个真实数据集的完整机器学习解决方案(上篇)提到,一个完整的机器学习工程的实现步骤:
1. 数据预处理
2. 探索性数据特征统计
3. 特征工程与特征选取
4. 建立基线
5. 机器学习建模
6. 超参数调优
7. 测试集验证
在上篇的内容中,我们介绍了第1到第4步的原理、代码以及实现(可视化)结果,接下来,我们将继续完成这个系列的文章,为大家介绍5-7步的详细原理、流程、代码。
机器学习建模在进行正式的机器学习建模前,我们还有两项前置工作需要完成。首先,在数据预处理的步骤中,我们剔除了缺失值大于一定比率的数据列,但是在剩下的数据列中,仍然存在着缺失值,对于这一小部分的缺失值,我们将不再丢弃相应的变量列,而是尝试对于缺失值进行填补。
我们读入上一步拆分好的训练数据集以及测试数据集
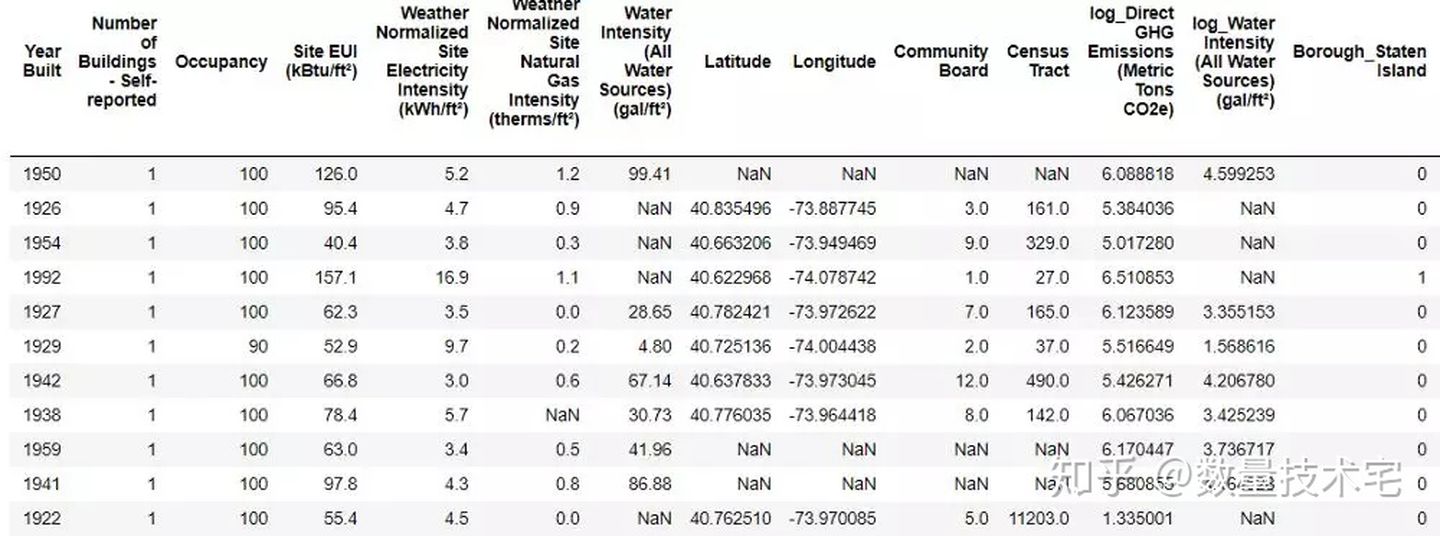
上图中的NaN,都代表着缺失的数据,我们采用一种简单的填补方式,即以每列数据的中位数(Median)作为数值,填充到NaN中。
我们借用Scikit-Learn库中封装好的函数创建了一个以“中位数值替换”(median)为填补策略的Imputer对象。然后,在训练集使用imputer.fit函数计算,用imputer.transform函数填充所有数据(训练集+测试集)中的缺失值。这里需要特别注意的是,测试集中的缺失值也将被相对应训练集中的中值所填充,只有这种填充方式,才能严格的避免测试数据集的数据泄露。这部分的关键实现代码我们也贴在了下图中。

第二项前置工作是数据的归一化,我们知道,真实世界中不同的数据往往有不同的量纲,而且量纲之间差距也很大,如果不做归一化,像支持向量机和K近邻这些会考虑各项特征之间距离的方法,会显著地受到不同特征量纲范围不同的影响。尽管某些模型,比如线性回归、随机森林,对特征量纲不敏感,但考虑到模型的安全性,我们还是建议,所有的建模测试前,都加入这一步骤。
归一化,具体来说,就是对特征的每一个值减去该特征对应的最小值并除以特征值区间(区间=最大值减最小值),我们借用Scikit-Learn中的MinMaxScale函数实现。为避免数据泄露,我们同样只使用训练数据计算区间、最大值和最小值,然后转换所有训练集和测试集的数据。

在做完缺失值填补、特征归一化,这两项前置工作后,接下来我们进入挑选机器学习模型的环节。目前,机器学习的模型日趋多元化,从大量现有的模型中选择最适用当前数据集的模型并不是一件容易的事。
尽管有些“模型分析流图”(以微软制作图为例)尝试指引你选择哪一种模型,但亲自去尝试多种算法,并根据实际的结果判断哪种模型效果最好,也许是更好的选择,机器学习可以说是一个主要由经验而不是理论驱动的领域。
虽然尝试模型的顺序无定式可言,但我们仍然可以遵循由简至繁的基本规律,即从简单的可解释模型(如线性回归)开始尝试,如果发现性能不足再转而使用更复杂但通常更准确的模型。一般来说,模型的可解释性与准确性,是几乎不可同时达到的两极,解释性强,意味着牺牲准确性,相反准确性强,意味着模型复杂化,解释力度变弱。