
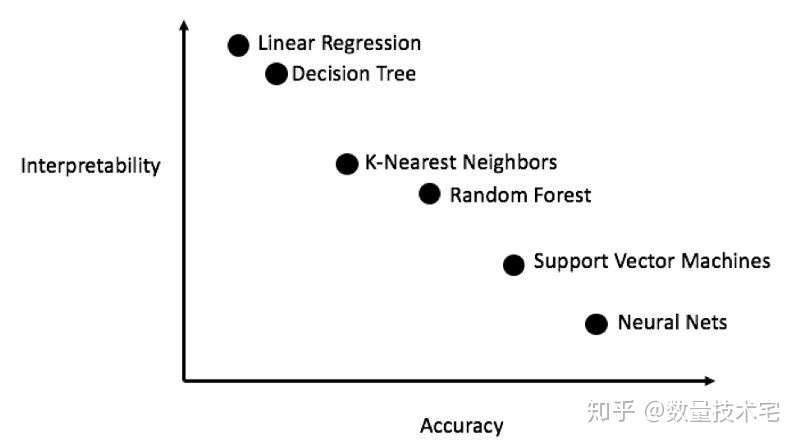
我们在综合考虑解释性、准确性的基础之上,对于本文所涉及的数据集,采用线性回归、K邻近、随机森林、梯度提升、支持向量机这5种主流的机器学习模型,进行逐一的建模和结果比较。
完成所有数据清洗与格式化工作后,接下来的模型创建、训练和预测工作反而相对简单,我们主要通过Scikit-Learn库(以下简称sklearn)完成,sklearn库有详细的帮助文档,对于各种机器学习的算法,大家都可以参考帮助文档相关的方法说明。
我们以梯度提升模型(Gradient Boosting Regressor)为例,为大家展示从创建模型,到训练模型,最后预测模型的这一过程,每个步骤,我们基本都可以借助sklearn库封装好的函数来完成。


对于其他的模型,我们只需要在构建模型的时候,调用不同的模型对应方法,即可在少量改写代码的前提下,完成所有模型的训练、评估。我们计算得到所有5个模型的Mae指标,并将该指标与基线(Baseline)进行比对。

回顾上文,我们此前计算得到的基线Mae指标的数值为24.5,上述5个模型的Mae都大幅低于基线数值,说明机器学习模型,在这个数据集上,对于最终的目标结果有比较显著的预测能力的改进。
再来对比5个模型相互之间的Mae,可以看到梯度提升模型的Mae最低,而线性回归模型的Mae最高,这也反应了我们此前讲述的逻辑,模型的可解释度(复杂程度)与预测能力是一个反向的关系。
超参数调优当然,在以上的模型训练中,我们根据经验设置了模型的超参数,并没有对这些参数进行调优处理。对于一个机器学习任务,在确定模型后,我们可以针对我们的任务调整模型超参数,以此来优化模型表现。
在超参数调优工作前,我们先简要介绍一下,超参数与普通参数定义的区别。机器学习中的超参数,通常被认为是数据科学家在训练之前对机器学习算法的设置,常见的有随机森林算法中树的个数或K-近邻算法中设定的邻居数等。
超参数的设定会直接影响模型“欠拟合”与“过拟合”的平衡,进而影响模型表现。欠拟合是指我们的模型不足够复杂(没有足够的自由度)去学习从特征到目标特征的映射。一个欠适合的模型有着很高的偏差(bias),我们可以通过增加模型的复杂度来纠正这种偏差(bias)。而过拟合则相反,它指的是我们的模型过度记忆了训练数据的情况,在样本外的测试集会与训练集有较大的偏差,对于过拟合,我们可以在模型中引入正则化的规则,在一定程度上加以避免。
对于不同的机器学习问题,每个问题都有其特有的最优超参数组合,不存在所有问题通用的最优解。因此,超参数的遍历、寻优,是找到最优超参数组合的唯一有效方式。我们同样借用sklearn库中的相关函数完成超参数的寻优,并通过随机搜索(Random Search)、交叉验证(Cross Validation)这两种方法实现。