
随机搜索(Random Search)是指,定义一个网格后采用随机抽样的方式,选取不同的超参数组合,随机搜索相比较普通的全网格搜索,在不影响优化性能的前提下,大幅减少了参数寻优的时间。
交叉验证(Cross Validation),又称为K折交叉验证,原始样本被随机划分为k等份子样本。在k份子样本中,依次保留一个子样本作为测试模型的验证集,剩下的k-1子样本用作模型训练,重复进行k次(the folds)交叉验证过程,每一个子样本都作为验证数据被使用一次。然后,这些折叠的k结果可以被平均(或其他组合)产生一个单一的估计。最后,我们将K次迭代的平均误差作为最终的性能指标。
我们还是以前文中举例的梯度提升回归模型(Gradient Boosted Regressor)为例,来演示随机搜索与交叉验证的过程。梯度提升回归模型(有多项超参数,具体可以查看sklearn库的官方文档以了解详细信息。我们对以下的超参数组合进行调优:
loss:损失函数的最小值设定
n_estimators:所使用的弱“学习者”(决策树)的数量
max_depth:决策树的最大深度
min_samples_leaf:决策树的叶节点所需的最小示例个数
min_samples_split:分割决策树节点所需的最小示例个数
max_features:最多用于分割节点的特征个数
首先确定各个超参数的遍历范围取值,以构建一个超参数寻优网络,对于梯度提升回归模型,我们选择如下的超参数寻优网络

紧接着,我们创建一个RandomizedSearchCV对象,通过sklearn库中的内置函数,采用4折交叉验证(cv=4),执行超参数寻优。

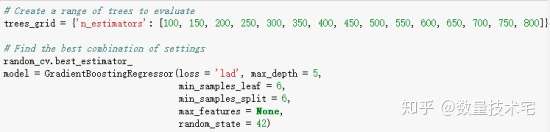
在完成超参数寻优的计算过程后,best_estimater方法将展示刚才寻优过程中找到的最佳超参数组合。
理论上,我们可以进行无限多次的超参数寻优,不断调整超参数的范围以找到最优解,但技术宅不建议大家过度去执行这个步骤,对于一个机器学习模型来说,优秀的特征工程,其重要性要远大于广泛的超参数寻优遍历。机器学习的收益递减规律是指,特征工程能对模型有较大提升,而超参调整则只能起到锦上添花的效果。
对于单一参数的调整寻优,我们也可以通过图形可视化的方式进行观察,比如下图我们仅改变决策树的数量,来观察模型的表现变化情况。
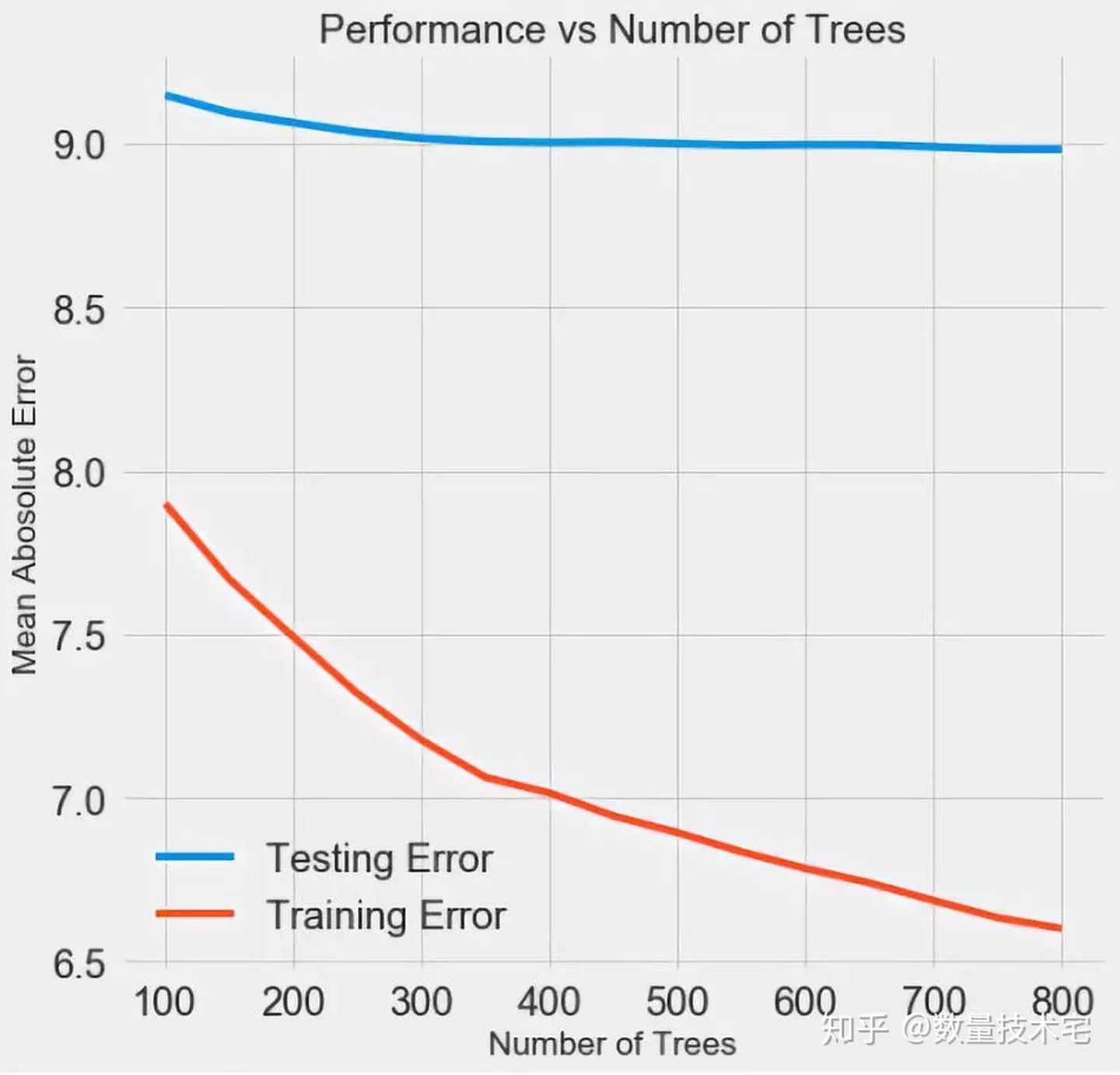
随着模型使用的树的个数增加,训练集误差和测试集误差都会减少。但我们需要看到虽然训练集的误差一直在减少,但测试集的误差,在树的数量到达300-400后,几乎不下降了。这就说明过度增加决策树的个数,最终带来的只是在训练集上的过度拟合,而对测试集没有什么增量的帮助。
针对这种情况,一方面我们可以增加样本的数量,获取更多的数据用于训练、测试,另一方面,我们也可以适当降低模型的复杂度。
测试集验证在此前所有的数据处理和建模的步骤中,我们都需要杜绝数据泄露的情况发生,只有这样,我们才能在测试集上准确、客观地评估模型的最终性能。
我们对比超参数寻优前、寻优后,两个模型在测试集上的表现,并以Mae作为评估指标。