RpcEndpoint:RPC端点,Spark针对每个节点(Client/Master/Worker)都称之为一个Rpc 端点,且都实现RpcEndpoint接口,内部根据不同端点的需求,设计不同的消息和不同的业务处理,如果需要发送(询问)则调用 Dispatcher;
RpcEnv:RPC上下文环境,每个RPC端点运行时依赖的上下文环境称为 RpcEnv;
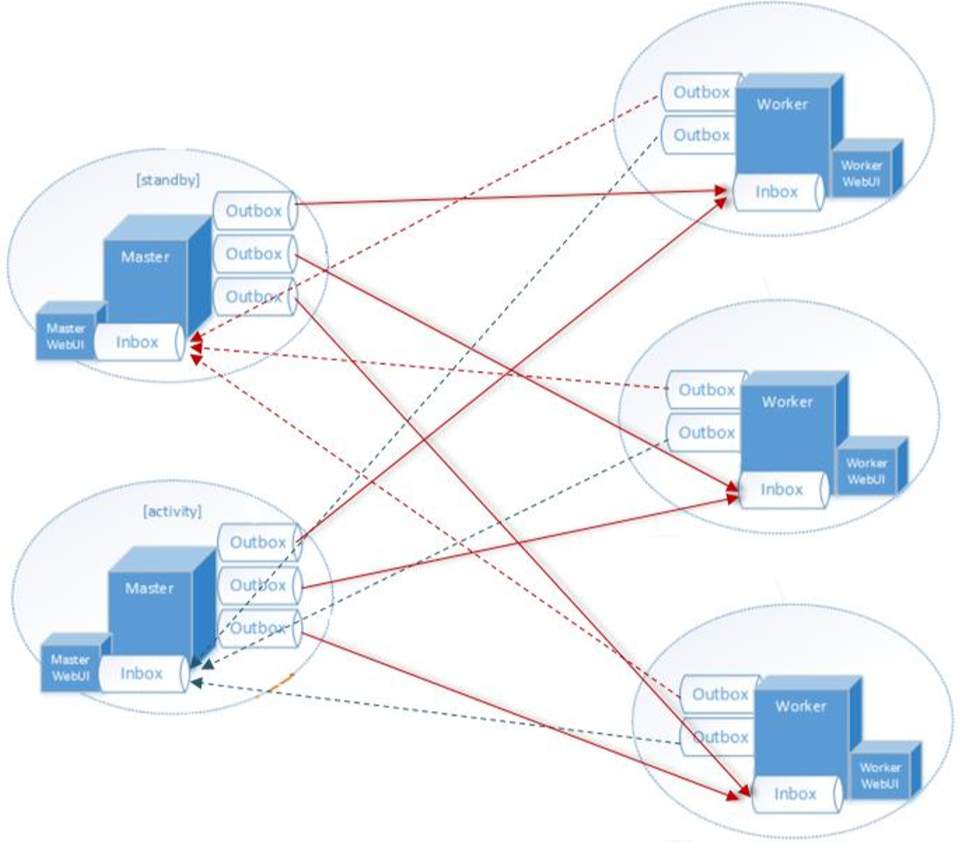
Dispatcher:消息分发器,针对于RPC端点需要发送消息或者从远程 RPC 接收到的消息,分发至对应的指令收件箱/发件箱。如果指令接收方是自己则存入收件箱,如果指令接收方不是自己,则放入发件箱;
Inbox:指令消息收件箱,一个本地RpcEndpoint对应一个收件箱,Dispatcher在每次向Inbox存入消息时,都将对应EndpointData加入内部ReceiverQueue中,另外Dispatcher创建时会启动一个单独线程进行轮询ReceiverQueue,进行收件箱消息消费;
RpcEndpointRef:RpcEndpointRef是对远程RpcEndpoint的一个引用。当我 们需要向一个具体的RpcEndpoint发送消息时,一般我们需要获取到该RpcEndpoint的引用,然后通过该应用发送消息。
OutBox:指令消息发件箱,对于当前RpcEndpoint来说,一个目标RpcEndpoint对应一个发件箱,如果向多个目标RpcEndpoint发送信息,则有多个OutBox。当消息放入Outbox后,紧接着通过TransportClient将消息发送出去。消息放入发件箱以及发送过程是在同一个线程中进行;
RpcAddress:表示远程的RpcEndpointRef的地址,Host + Port。
TransportClient:Netty通信客户端,一个OutBox对应一个TransportClient,TransportClient不断轮询OutBox,根据OutBox消息的receiver信息,请求对应的远程TransportServer;
TransportServer:Netty通信服务端,一个RpcEndpoint对应一个TransportServer,接受远程消息后调用 Dispatcher分发消息至对应收发件箱;
根据上面的分析,Spark通信架构的高层视图如下图所示:
在Spark中由SparkContext负责与集群进行通讯、资源的申请以及任务的分配和监控等。当 Worker节点中的Executor运行完毕Task后,Driver同时负责将SparkContext关闭。
通常也可以使用SparkContext来代表驱动程序(Driver)。
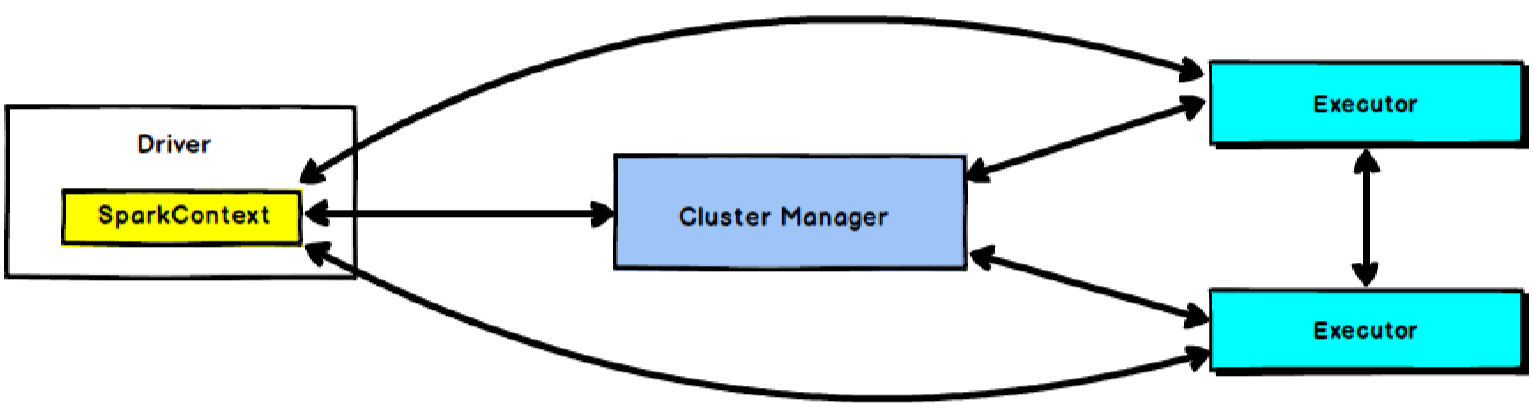
SparkContext是用户通往Spark集群的唯一入口,可以用来在Spark集群中创建RDD、累加器和广播变量。
SparkContext也是整个Spark应用程序中至关重要的一个对象,可以说是整个Application运行调度的核心(不包括资源调度)。
SparkContext的核心作用是初始化Spark应用程序运行所需的核心组件,包括高层调度器(DAGScheduler)、底层调度器(TaskScheduler)和调度器的通信终端(SchedulerBackend),同时还会负责Spark程序向Cluster Manager的注册等。
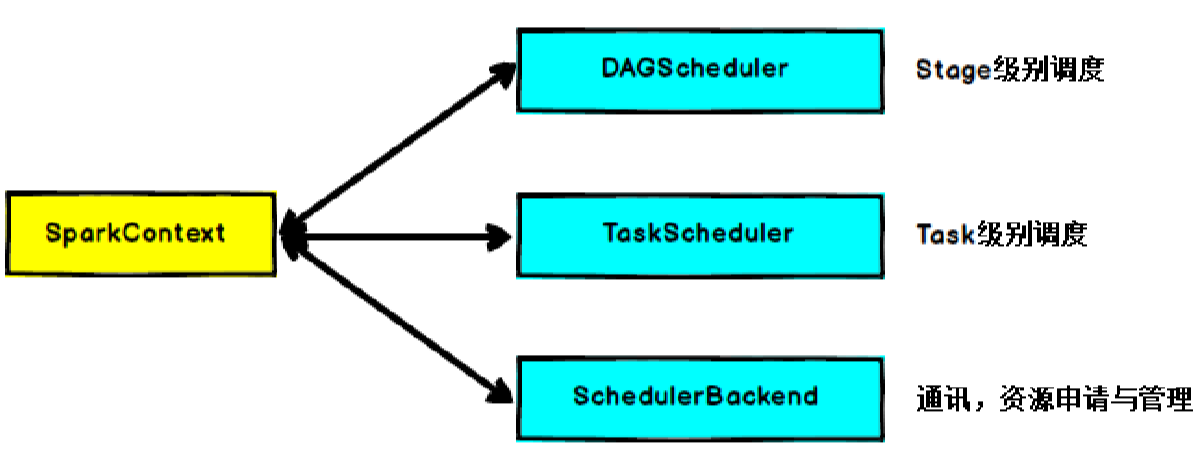
在实际的编码过程中,我们会先创建SparkConf实例,并对SparkConf的属性进行自定义设置,随后,将SparkConf作为SparkContext类的唯一构造参数传入来完成SparkContext实例对象的创建。SparkContext在实例化的过程中会初始化DAGScheduler、TaskScheduler和SchedulerBackend,当RDD的action算子触发了作业(Job)后,SparkContext会调用DAGScheduler根据宽窄依赖将Job划分成几个小的阶段(Stage),TaskScheduler会调度每个Stage的任务(Task),另外,SchedulerBackend负责申请和管理集群为当前Application分配的计算资源(即Executor)。
如果我们将Spark Application比作汽车,那么SparkContext就是汽车的引擎,而SparkConf就是引擎的配置参数。
下图描述了Spark-On-Yarn模式下在任务调度期间,ApplicationMaster、Driver以及Executor内部模块的交互过程:
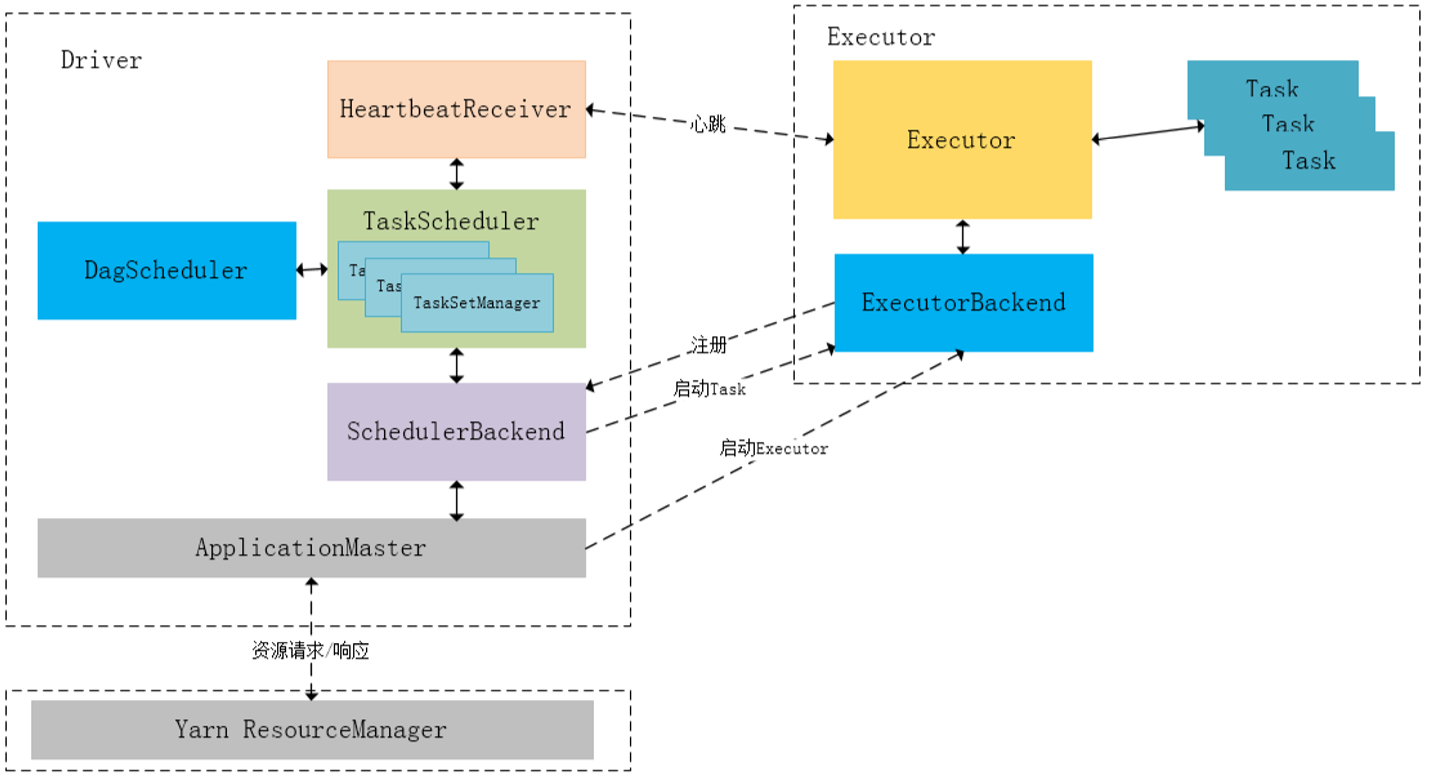
Driver初始化SparkContext过程中,会分别初始化DAGScheduler、TaskScheduler、SchedulerBackend以及HeartbeatReceiver,并启动SchedulerBackend以及HeartbeatReceiver。SchedulerBackend通过ApplicationMaster申请资源,并不断从TaskScheduler中拿到合适的Task分发到Executor执行。HeartbeatReceiver负责接收Executor的心跳信息,监控Executor的存活状况,并通知到TaskScheduler。
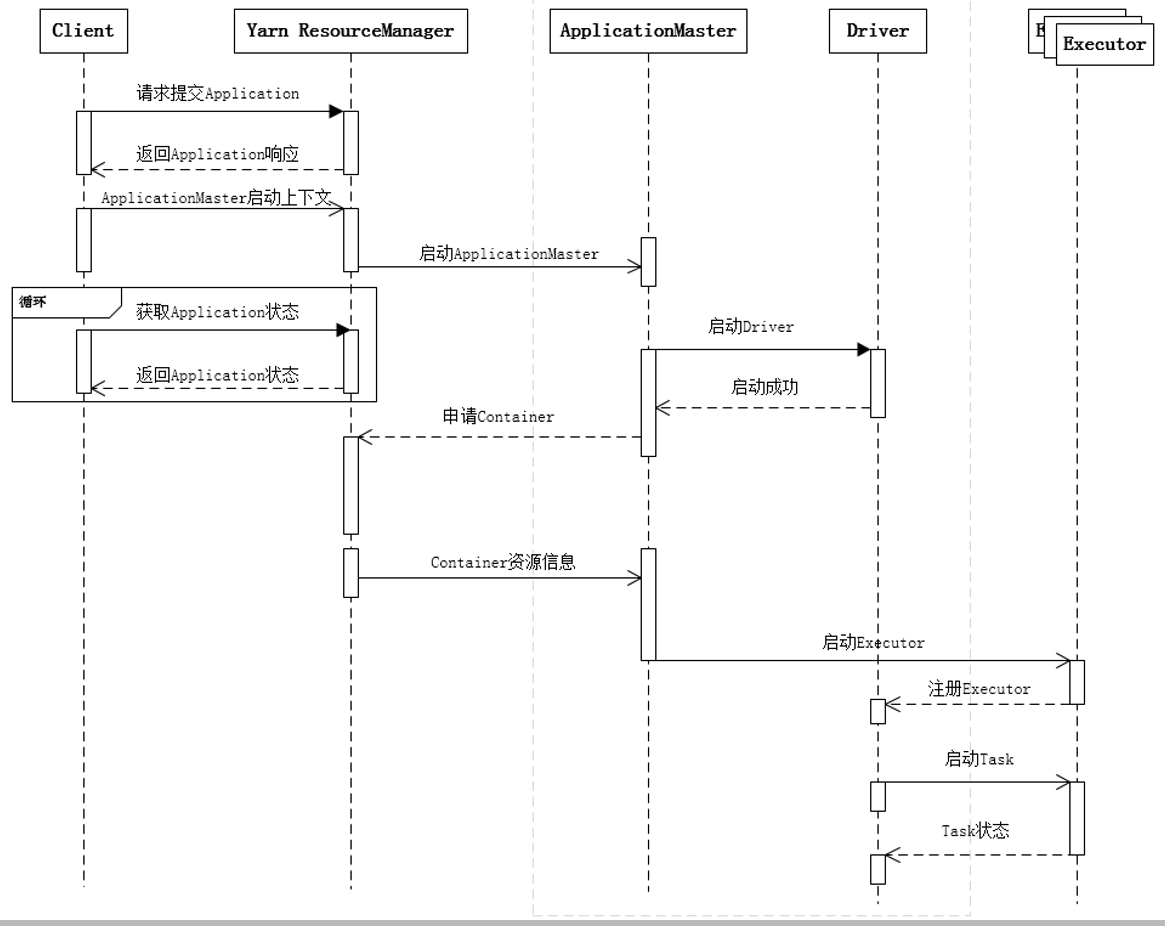
五、Spark任务调度机制在工厂环境下,Spark集群的部署方式一般为YARN-Cluster模式,之后的内核分析内容中我们默认集群的部署方式为YARN-Cluster模式。
Spark任务提交流程
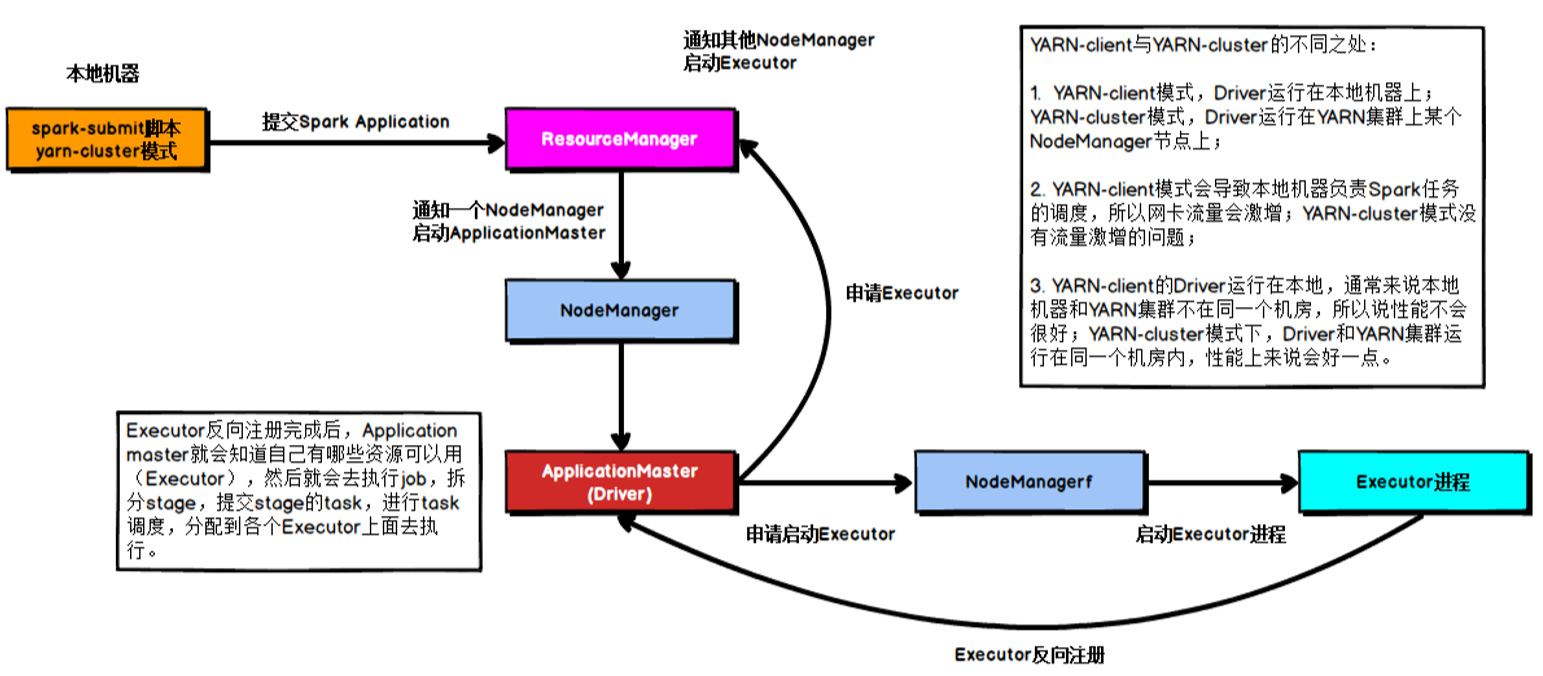
Spark YARN-Cluster模式下的任务提交流程
下面的时序图清晰地说明了一个Spark应用程序从提交到运行的完整流程: