
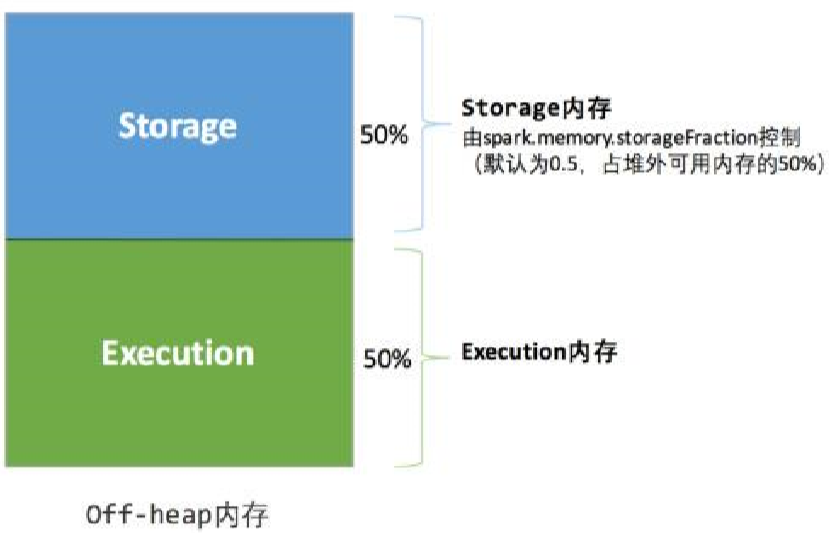
堆外的空间分配较为简单,只有存储内存和执行内存。可用的执行内存和存储内存占用的空间大小直接由参数spark.memory.storageFraction决定,由于堆外内存占用的空间可以被精确计算,所以无需再设定保险区域。
静态内存管理机制实现起来较为简单,但如果用户不熟悉Spark的鵆机制,或没有根据具体的数据规模和计算任务或做相应的配置,很容易造成“一般海水,一般火焰”的局面,即存储内存和执行内存中的一方剩余大量的空间,而另一方却早早被占满,不得不淘汰或移出旧的内容以存储新的内容。由于新的内存管理机制的出现,这种方式目前已经很少有开发者使用,出于兼容旧版本的应用程序的目的,Spark依然保留了它的实现。
2、统一内存管理
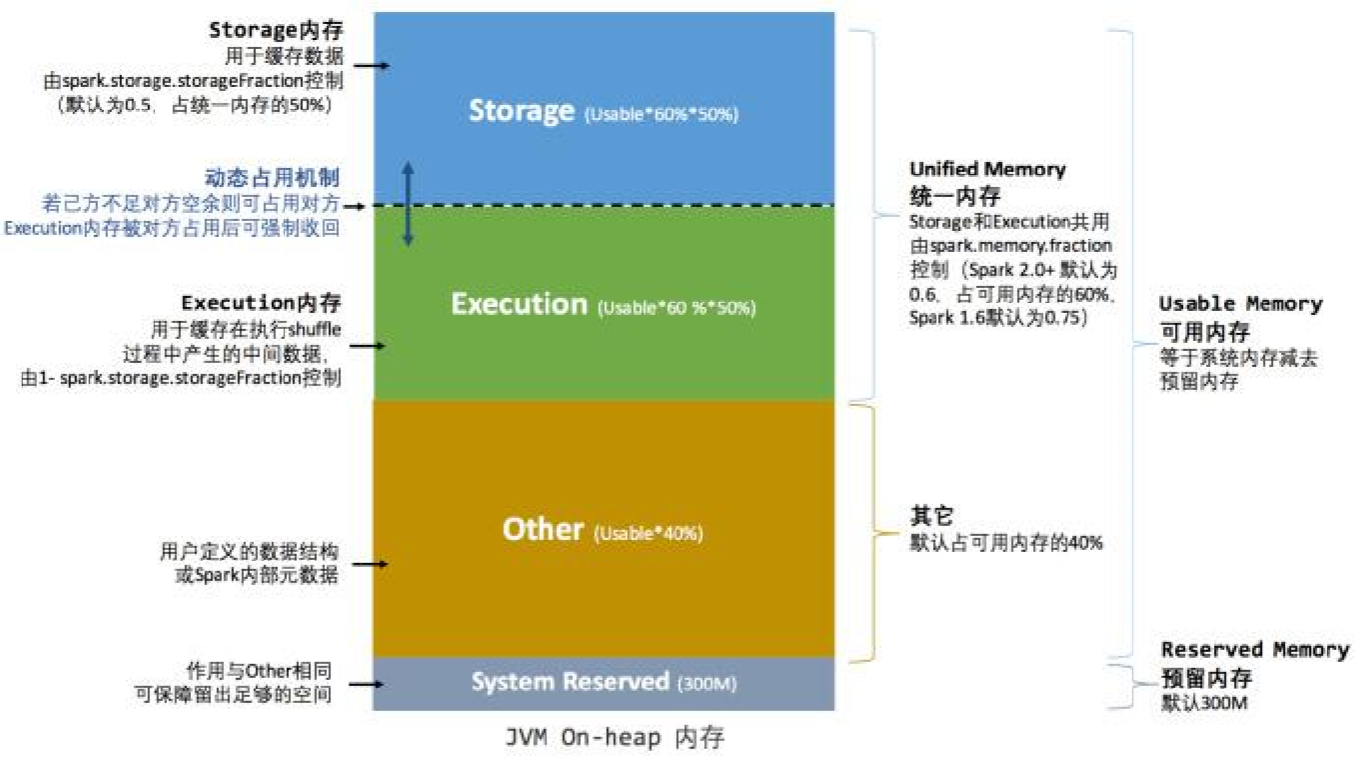
Spark1.6之后引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域,统一内存管理的堆内内存结构如下图所示:
统一内存管理的堆外内存结构如下图所示:
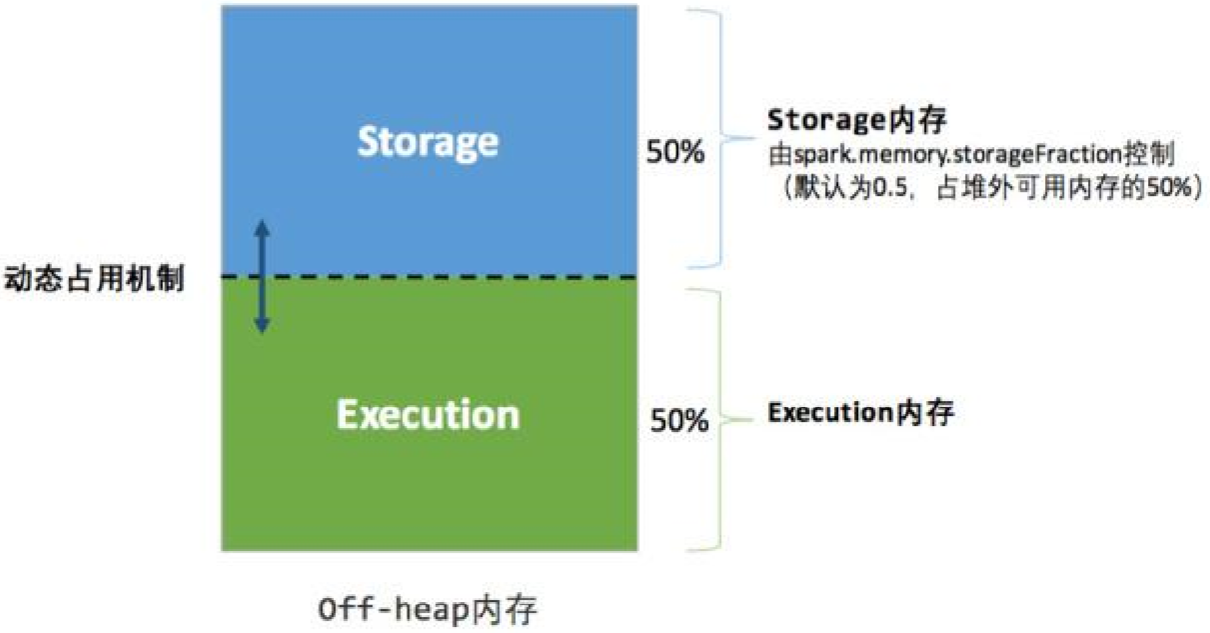
其中最重要的优化在于动态占用机制,其规则如下:
1、设定基本的存储内存和执行内存区域(spark.storage.storageFraction参数),该设定确定了双方各自拥有的空间的范围;
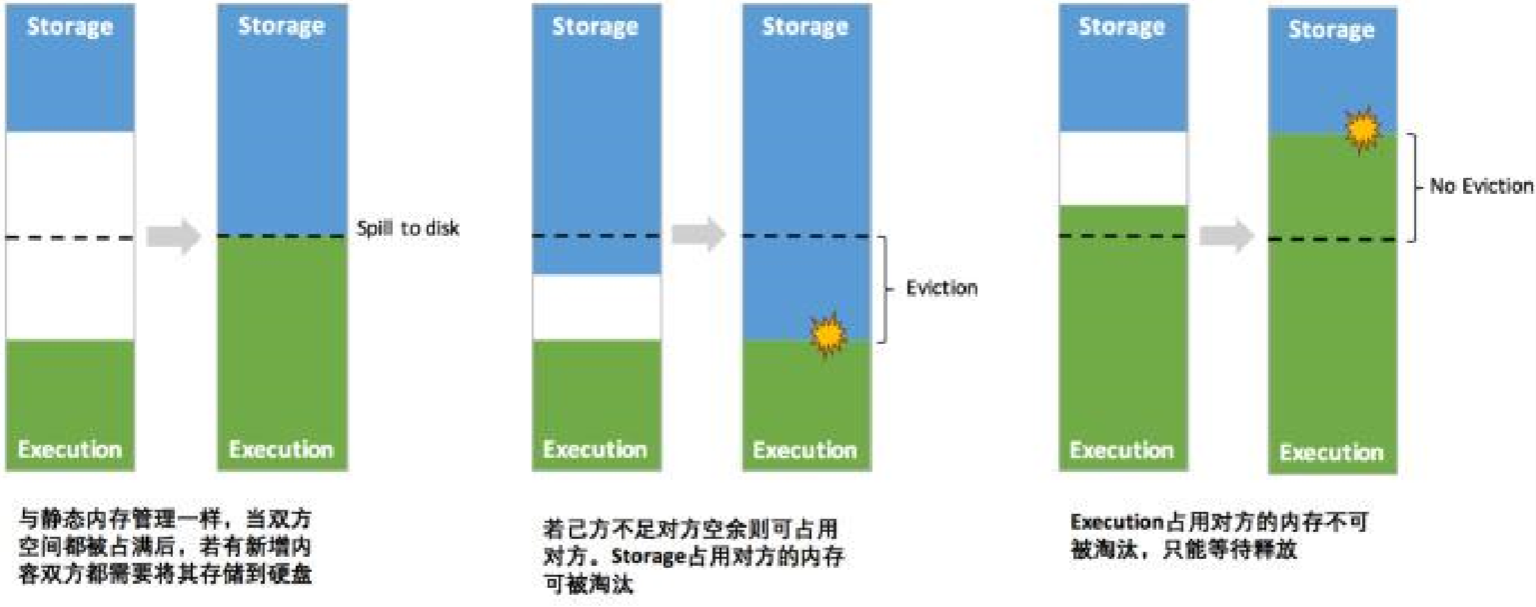
2、双方的空间都不足时,则存储到磁盘;若己方空间不足而对方空余时,可借用对方的空间;(存储空间不足是指不足以放下一个完整的Block)
3、执行内存的空间被对方占用后,可让对方将占用的部分转存到磁盘,然后“归还”借用的空间;
4、存储内存的空间被对方占用后,无法让对方“归还”,因为需要考虑Shuffle过程中的很多因素,实现起来较为复杂。
统一内存管理的动态占用机制如下图所示:
凭借统一内存管理机制,spark在一定程度上提高了堆内和堆外内存资源的利用率,降低了开发者维护spark内存的难度。如果存储内存的空间太大或者说缓存的数据过多,反而会导致频繁的全量垃圾回收,降低任务执行时的性能,因为缓存的RDD数据通常都是长期主流内存的。所以要想充分发挥Spark的性能,需要开发者进一步了解存储内存和执行内存各自管理方式和实现原理。
存储内存管理
1、RDD持久化机制
弹性分布式数据集(RDD)作为Spark最根本的数据抽象,是只读的分区记录(Partition)的集合,只能基于在稳定物理存储中的数据集上创建,或者在其他已有的RDD上执行转换(Transformation)操作产生一个新的RDD。转换后的RDD与原始的RDD之间产生了依赖关系,构成了血统(Lineage)。凭借血统,Spark保证了每一个RDD都可以被重新恢复。但是RDD的所有转换都是有惰性的,即只有当一个返回结果给Driver的行动(Action)发生时,Spark才会创建任务读取RDD,然后真正触发转换的执行。
Task在启动之初读取一个分区时,会先判断这个分区是否已经被持久化,如果没有则需要检查Checkpoint或按照血统重新计算。所以如果一个RDD上要执行多次行动,可以在第一次行动中使用persist或cache方法,在内存或磁盘中持久化或缓存这个RDD,从而在后面的行动中提升计算速度。
事实上,cache方法是使用默认的MEMORY_ONLY的存储级别将RDD持久化到内存,故缓存是一种特殊的持久化。堆内和堆外存储内存的设计,便可以对缓存RDD时使用的内存做统一的规划和管理。