又到了年底跳槽高峰季,很多小伙伴出去面试时,不少面试官都会问到消息队列的问题,不少小伙伴回答的不是很完美,有些小伙伴是心里知道答案,嘴上却没有很好的表达出来,究其根本原因,还是对相关的知识点理解的不够透彻。今天,我们就一起来探讨下这个话题。注:文章有点长,你说你能一鼓作气看完,我有点不信!!
文章已收录到:
https://github.com/sunshinelyz/technology-binghe
https://gitee.com/binghe001/technology-binghe
什么是消息队列?消息队列(Message Queue)是在消息的传输过程中保存消息的容器,是应用间的通信方式。消息发送后可以立即返回,由消息系统保证消息的可靠传输,消息发布者只管把消息写到队列里面而不用考虑谁需要消息,而消息的使用者也不需要知道谁发布的消息,只管到消息队列里面取,这样生产和消费便可以做到分离。
为什么要使用消息队列?优点:
异步处理:例如短信通知、终端状态推送、App推送、用户注册等
数据同步:业务数据推送同步
重试补偿:记账失败重试
系统解耦:通讯上下行、终端异常监控、分布式事件中心
流量消峰:秒杀场景下的下单处理
发布订阅:HSF的服务状态变化通知、分布式事件中心
高并发缓冲:日志服务、监控上报
使用消息队列比较核心的作用就是:解耦、异步、削峰。
缺点:
系统可用性降低 系统引入的外部依赖越多,越容易挂掉?如何保证消息队列的高可用?
系统复杂度提高 怎么保证消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的顺序性?
一致性问题 A 系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是 BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,咋整?你这数据就不一致了。
以下主要讨论的RabbitMQ和Kafka两种消息队列。
如何保证消息队列的高可用? RabbitMQ的高可用RabbitMQ的高可用是基于主从(非分布式)做高可用性。RabbitMQ 有三种模式:单机模式(Demo级别)、普通集群模式(无高可用性)、镜像集群模式(高可用性)。
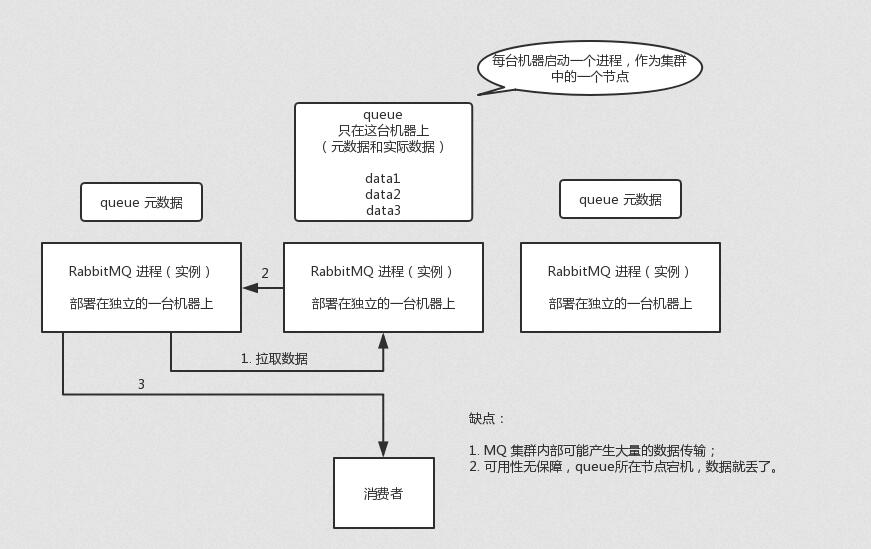
普通集群模式
普通集群模式,意思就是在多台机器上启动多个 RabbitMQ 实例,每个机器启动一个。你创建的 queue,只会放在一个 RabbitMQ 实例上,但是每个实例都同步 queue 的元数据(元数据可以认为是 queue 的一些配置信息,通过元数据,可以找到 queue 所在实例)。你消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从 queue 所在实例上拉取数据过来。
这种方式确实很麻烦,也不怎么好,没做到所谓的分布式,就是个普通集群。因为这导致你要么消费者每次随机连接一个实例然后拉取数据,要么固定连接那个 queue 所在实例消费数据,前者有数据拉取的开销,后者导致单实例性能瓶颈。
而且如果那个放 queue 的实例宕机了,会导致接下来其他实例就无法从那个实例拉取,如果你开启了消息持久化,让 RabbitMQ 落地存储消息的话,消息不一定会丢,得等这个实例恢复了,然后才可以继续从这个 queue 拉取数据。
所以这个事儿就比较尴尬了,这就没有什么所谓的高可用性,这方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个 queue 的读写操作。
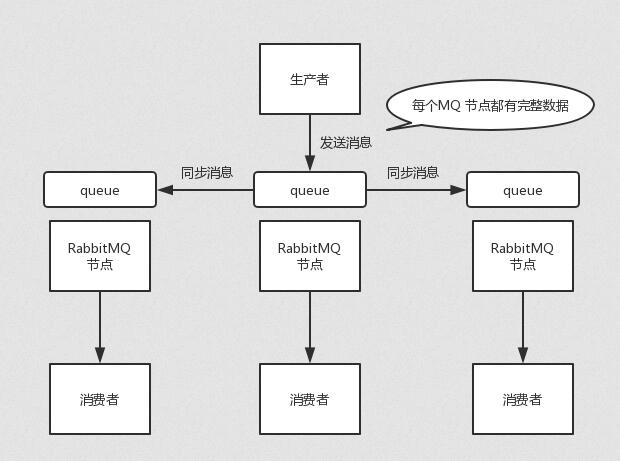
镜像集群模式
这种模式,才是所谓的 RabbitMQ 的高可用模式。跟普通集群模式不一样的是,在镜像集群模式下,你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,就是说,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据的意思。然后每次你写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。
那么如何开启这个镜像集群模式呢?其实很简单,RabbitMQ 有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候是可以要求数据同步到所有节点的,也可以要求同步到指定数量的节点,再次创建 queue 的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。
这样的话,好处在于,你任何一个机器宕机了,没事儿,其它机器(节点)还包含了这个 queue 的完整数据,别的 consumer 都可以到其它节点上去消费数据。坏处在于,第一,这个性能开销也太大了吧,消息需要同步到所有机器上,导致网络带宽压力和消耗很重!第二,这么玩儿,不是分布式的,就没有扩展性可言了,如果某个 queue 负载很重,你加机器,新增的机器也包含了这个 queue 的所有数据,并没有办法线性扩展你的 queue。你想,如果这个 queue 的数据量很大,大到这个机器上的容量无法容纳了,此时该怎么办呢?