这里先引入一个基本的案例来演示流的创建:获取指定端口上的数据并进行词频统计。项目依赖和代码实现如下:
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.12</artifactId> <version>2.4.3</version> </dependency> import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext} object NetworkWordCount { def main(args: Array[String]) { /*指定时间间隔为 5s*/ val sparkConf = new SparkConf().setAppName("NetworkWordCount").setMaster("local[2]") val ssc = new StreamingContext(sparkConf, Seconds(5)) /*创建文本输入流,并进行词频统计*/ val lines = ssc.socketTextStream("hadoop001", 9999) lines.flatMap(_.split(" ")).map(x => (x, 1)).reduceByKey(_ + _).print() /*启动服务*/ ssc.start() /*等待服务结束*/ ssc.awaitTermination() } }使用本地模式启动 Spark 程序,然后使用 nc -lk 9999 打开端口并输入测试数据:
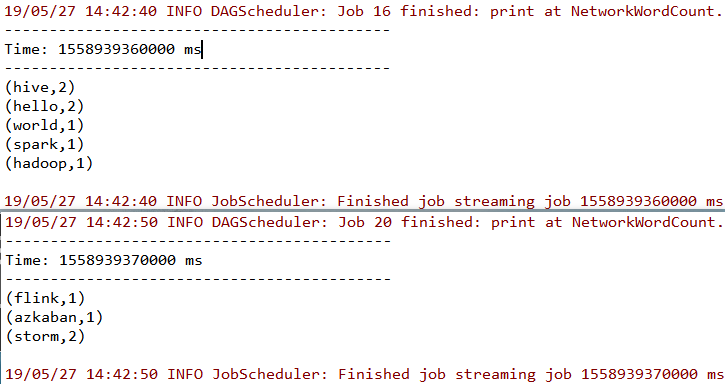
[root@hadoop001 ~]# nc -lk 9999 hello world hello spark hive hive hadoop storm storm flink azkaban此时控制台输出如下,可以看到已经接收到数据并按行进行了词频统计。