文本序列类型(str)
在Python语言中,文本数据由str对象或strings进行处理。字符串是不可变的Unicode码点序列。字符串字面值的写法有多种方式,例如:
单引号('):在单引号中允许嵌入一对双引号。
双引号("):允许嵌入一对单引号。
三引号('''):可以是三个单引号(''')的用法,也可以是三个双引号(""")的用法。三引号字符串可以跨越多行,引号内的空格也会包含在字符串中。
如果多个字符串字面值都是单个表达式的一个部分并且它们之间只有空格,那么它们将被隐式转换为单个字符串字面值。也就是说,("spam " "eggs") == "spam eggs"。
方法str.capitalize()在Python语言中,方法str.capitalize()的功能是返回字符串的副本,该副本第一个字符大写,其余字符小写。例如在下面的实例文件linuxidc01.py中,演示了使用方法str.capitalize()处理字符串的过程。
#使用capitalize()方法 s = 'a, B' print(s.capitalize()) s = ' a, B' # a 前面有空格 print(s.capitalize()) s = 'a, BCD' print(s.capitalize())执行后会输出:
A, b
a, b
A, bcd

在Python语言中,str.casefold()的功能是返回字符串的小写形式,其功能和小写方法lower()相同,但casefold()的功能更强大,因为它旨在删除字符串中的所有case区别。例如,德国小写字母'ß'等效于"ss"。由于它已经是小写的,所以lower()对'ß'不起作用,而函数casefold()能够将其转换为"ss"。
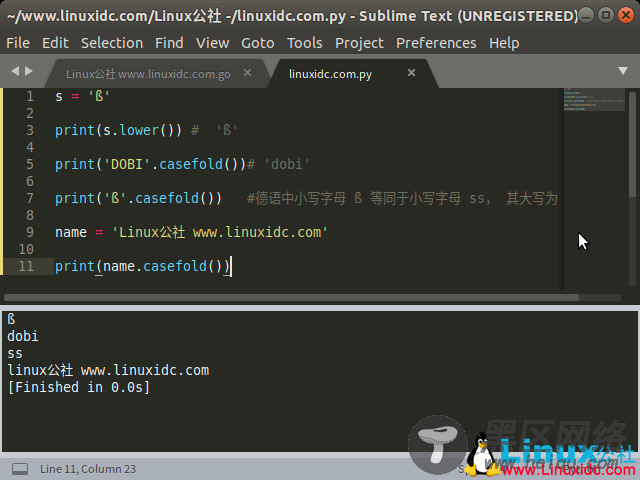
例如在下面的实例文件linuxidc02.py中,演示了使用方法str.casefold()处理字符串的过程。
s = 'ß' print(s.lower()) # 'ß' print('DOBI'.casefold())# 'dobi' print('ß'.casefold()) #德语中小写字母 ß 等同于小写字母 ss, 其大写为 SS name = 'Linux公社 ' print(name.casefold())执行后会输出:
ß
dobi
ss
Linux公社
在Python语言中,方法str.count(sub[, start[, end]])的功能是返回在[start, end]范围内的子串sub非重叠出现的次数。可选参数start和end都以切片表示法解释,分别表示字符串的开始和结束限定范围。
sub:搜索的子字符串;
start:字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0;
end:字符串中结束搜索的位置。字符中第一个字符的索引为0。默认为字符串的最后一个位置。
例如在下面的实例文件linuxidc03.py中,演示了使用方法str.count()处理字符串的过程。
str = "this is string example....wow!!!"; sub = "i"; print("str.count(sub, 4, 40) : ", str.count(sub, 4, 40)) sub = "wow"; print("str.count(sub) : ", str.count(sub))执行后会输出:
str.count(sub, 4, 40) : 2 str.count(sub) : 1 方法str.encode()在Python语言中,方法str.encode(encoding="utf-8", errors="strict")的功能是将字符串的编码版本作为字节对象返回,默认编码为'utf-8'。errors的默认值是'strict',意思编码错误引发一个UnicodeError。
encoding:要使用的编码,如"UTF-8"。
errors:设置不同错误的处理方案,默认为 'strict',意为编码错误引起一个UnicodeError。 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通过 codecs.register_error() 注册的任何值。
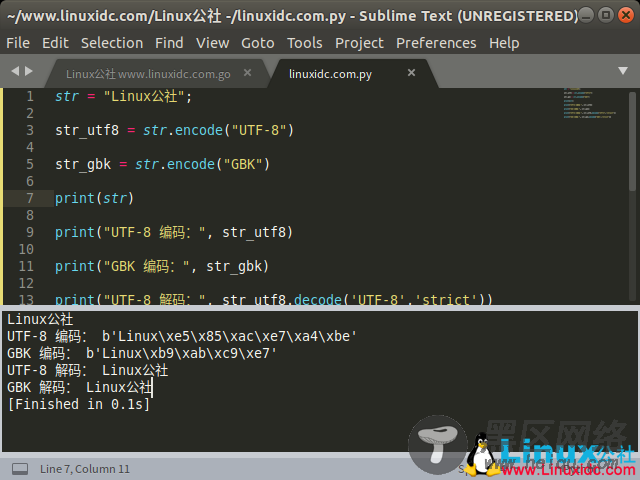
例如在下面的实例文件linuxidc04.py中,演示了使用方法str. encode()处理字符串的过程。
str = "Linux公社"; str_utf8 = str.encode("UTF-8") str_gbk = str.encode("GBK") print(str) print("UTF-8 编码:", str_utf8) print("GBK 编码:", str_gbk) print("UTF-8 解码:", str_utf8.decode('UTF-8','strict')) print("GBK 解码:", str_gbk.decode('GBK','strict'))执行后会输出:
Linux公社
UTF-8 编码: b'Linux\xe5\x85\xac\xe7\xa4\xbe'
GBK 编码: b'Linux\xb9\xab\xc9\xe7'
UTF-8 解码: Linux公社
GBK 解码: Linux公社