
AI前线导读:本文是 **Apache Beam实战指南系列文章** 的第二篇内容,将重点介绍 Apache Beam与Flink的关系,对Beam框架中的KafkaIO和Flink源码进行剖析,并结合应用示例和代码解读带你进一步了解如何结合Beam玩转Kafka和Flink。系列文章第一篇回顾Apache Beam实战指南之基础入门
关于Apache Beam实战指南系列文章
随着大数据 2.0 时代悄然到来,大数据从简单的批处理扩展到了实时处理、流处理、交互式查询和机器学习应用。近年来涌现出诸多大数据应用组件,如 HBase、Hive、Kafka、Spark、Flink 等。开发者经常要用到不同的技术、框架、API、开发语言和 SDK 来应对复杂应用的开发,这大大增加了选择合适工具和框架的难度,开发者想要将所有的大数据组件熟练运用几乎是一项不可能完成的任务。
面对这种情况,Google 在 2016 年 2 月宣布将大数据流水线产品(Google DataFlow)贡献给 Apache 基金会孵化,2017 年 1 月 Apache 对外宣布开源 Apache Beam,2017 年 5 月迎来了它的第一个稳定版本 2.0.0。在国内,大部分开发者对于 Beam 还缺乏了解,社区中文资料也比较少。InfoQ 期望通过 **Apache Beam 实战指南系列文章** 推动 Apache Beam 在国内的普及。
一.概述大数据发展趋势从普通的大数据,发展成AI大数据,再到下一代号称万亿市场的lOT大数据。技术也随着时代的变化而变化,从Hadoop的批处理,到Spark Streaming,以及流批处理的Flink的出现,整个大数据架构也在逐渐演化。
Apache Beam作为新生技术,在这个时代会扮演什么样的角色,跟Flink之间的关系是怎样的?Apache Beam和Flink的结合会给大数据开发者或架构师们带来哪些意想不到的惊喜呢?
二.大数据架构发展演进历程 2.1 大数据架构Hadoop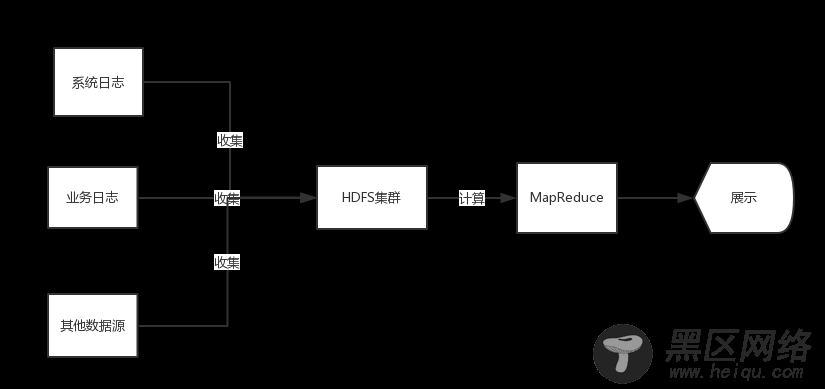
图2-1 MapReduce 流程图
最初做大数据是把一些日志或者其他信息收集后写入Hadoop 的HDFS系统中,如果运营人员需要报表,则利用Hadoop的MapReduce进行计算并输出,对于一些非计算机专业的统计人员,后期可以用Hive进行统计输出。
2.2 流式处理Storm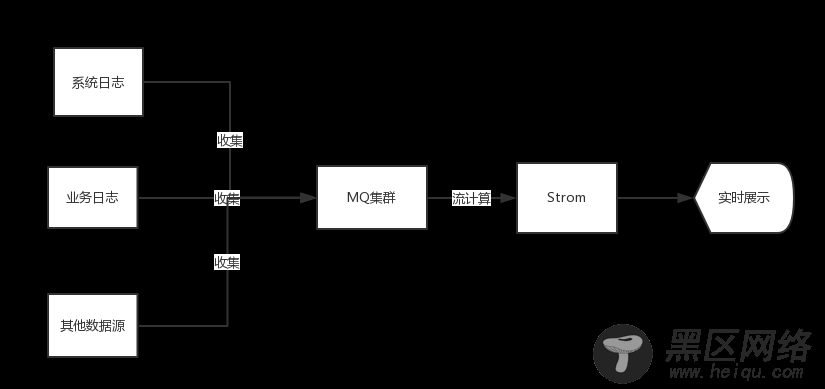
图2-2Storm流程图
业务进一步发展,运营人员需要看到实时数据的展示或统计。例如电商网站促销的时候,用于统计用户实时交易数据。数据收集也使用MQ,用流式Storm解决这一业务需求问题。
2.3 Spark批处理和微批处理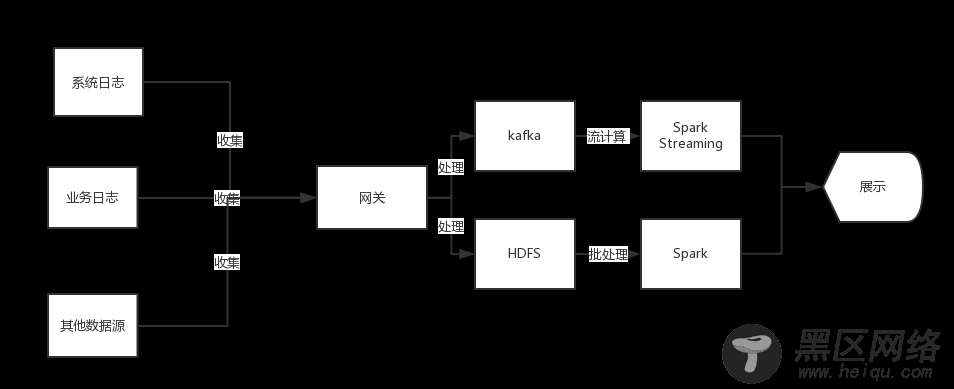
图2-3 Spark流程图
业务进一步发展,服务前端加上了网关进行负载均衡,消息中心也换成了高吞吐量的轻量级MQ Kafka,数据处理渐渐从批处理发展到微批处理。
2.4 Flink:真正的流批处理统一
图2-4 Flink 流程图
随着AI和loT的发展,对于传感设备的信息、报警器的警情以及视频流的数据量微批计算引擎已经满足不了业务的需求,Flink实现真正的流处理让警情更实时。
2.5 下一代大数据处理统一标准Apache Beam
图2-5 Apache Beam 流程图
BeamSDKs封装了很多的组件IO,也就是图左边这些重写的高级API,使不同的数据源的数据流向后面的计算平台。通过将近一年的发展,Apache Beam 不光组件IO更加丰富了,并且计算平台在当初最基本的 Apache Apex、Direct Runner、Apache Flink、Apache Spark、Google Cloud Dataflow之上,又增加了Gearpump、Samza 以及第三方的JStorm等计算平台。
为什么说Apache Beam 会是大数据处理统一标准呢?
因为很多现在大型公司都在建立自己的“大中台”,建立统一的数据资源池,打通各个部门以及子公司的数据,以解决信息孤岛问题,把这些数据进行集中式管理并且进行后期的数据分析、BI、AI以及机器学习等工作。这种情况下会出现很多数据源,例如之前用的MySQL、MongodDB、HDFS、HBase、Solr 等,如果想建立中台就会是一件令人非常苦恼的事情,并且多计算环境更是让技术领导头疼。Apache Beam的出现正好迎合了这个时代的新需求,它集成了很多数据库常用的数据源并把它们封装成SDK的IO,开发人员没必要深入学习很多技术,只要会写Beam 程序就可以了,大大节省了人力、时间以及成本。
三.Apache Beam和Flink的关系