
保证给你讲明白,看不懂你砍我。
首先弄明白两个概念-大概说一下,具体的网上都有:
覆盖索引-select b,c,d from t1 ;
select b,c,d from t1 where b=1 and c =1 and d=1 ;
select a,b,c,d from t1 where b=1 and c =1 and d=1;
【a是主键,给bcd建立联合索引】,如上几个sql,select出来的内容,和where条件字段,刚好和建立的索引一致.
回表-使用非聚簇索引进行查找数据时,需要根据主键值去聚簇索引中再查找一遍完整的用户记录,这个过程叫做回表.
上面两个概念清楚以后,继续往下看。
新建一张测试表 t1.如下。
备注:a列设置为主键列,bcd列建立联合索引,其他列暂时没有建立索引。
1 15 16 17 x
2 25 26 27 x
3 35 36 37 x
4 45 46 47 x
5 55 56 57 x
6 65 66 67 x
7 75 76 77 x
8 85 86 87 x
执行sql,如下:
select b,c,d from t1 where b=15 and c=16 and d=17
这里使用了 覆盖索引。我们看下他的B+树。
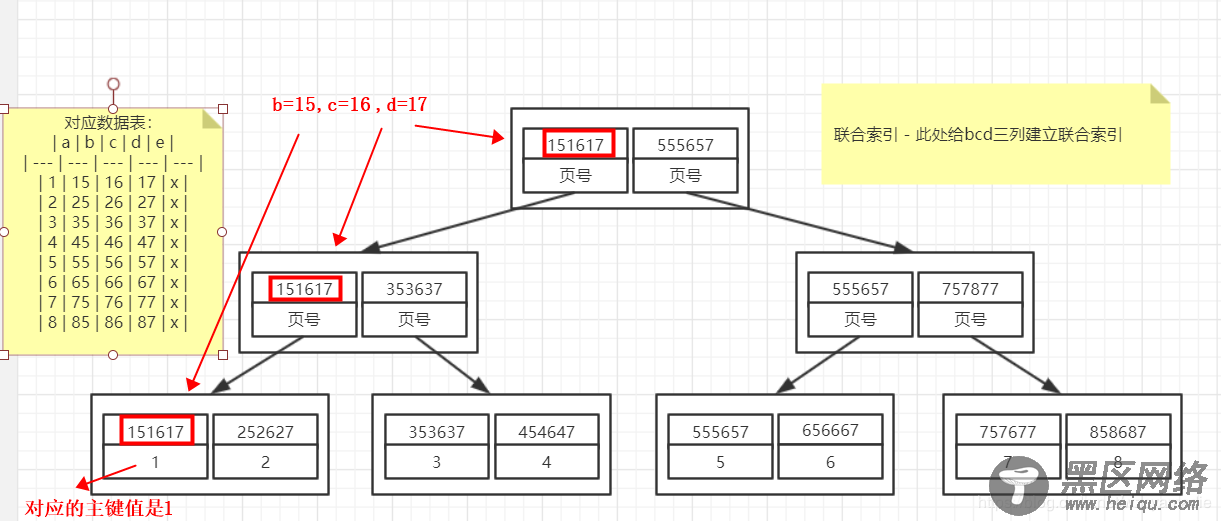
分析上图,满足条件的结果,是不是完整的显示在了叶子节点上???【注意:我们select查询的内容不是全表,是bcd三个字段,在叶子节点上,这3个字段是不是都已经有对应的值了。】
即使我们sql写这样子:
select a,b,c,d from t1 where b=15 and c=16 and d=17
a是主键列,但是在联合索引的叶子节点上,页存储了对应的主键值,所以依旧不需要回表操作。
总结:使用覆盖索引,我们需要select出来的列,都已经存在了索引树的叶子节点上。所以不需要回表操作,如果我们select出来的某列,不在该联合索引的叶子节点上(比如上表的e列),那就需要根据对应索引值,去聚簇索引树上回表查询对应的e列值了。
Linux公社的RSS地址:https://www.linuxidc.com/rssFeed.aspx