
我们通过 spark-ui 观察 Thread dump (这里通过手动刷新 spark-ui 或者登录 driver 节点使用 jstack 命令查看线程堆栈信息),发现这三个阶段都比较慢, 下面我们来分析这三部分的源码。
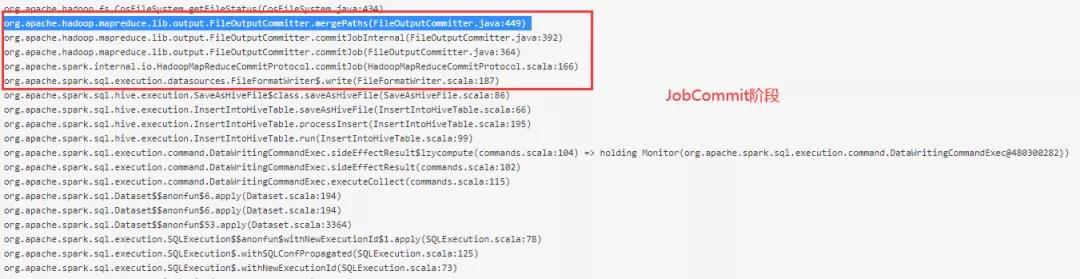
3. 源码分析 (1)JobCommit阶段
Spark 使用的是 Hadoop 的 FileOutputCommitter 来处理文件合并操作, Hadoop 2.x 默认使用 mapreduce.fileoutputcommitter.algorithm.version=1,使用单线程 for 循环去遍历所有 task 子目录,然后做 merge path 操作,显然在输出文件很多情况下,这部分操作会非常耗时。
特别是对对象存储来说,rename 操作并不仅仅是修改元数据,还需要去 copy 数据到新文件。
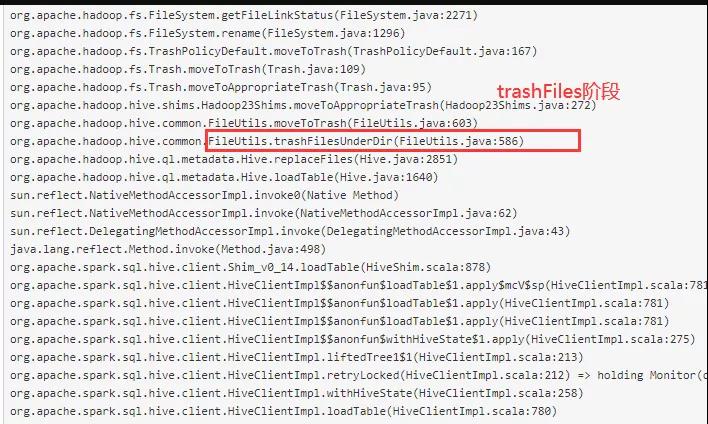
(2)TrashFiles阶段
trashFiles 操作是单线程 for 循环来将文件 move 到文件回收站,如果需要被覆盖写的数据比较多,这步操作会非常慢。
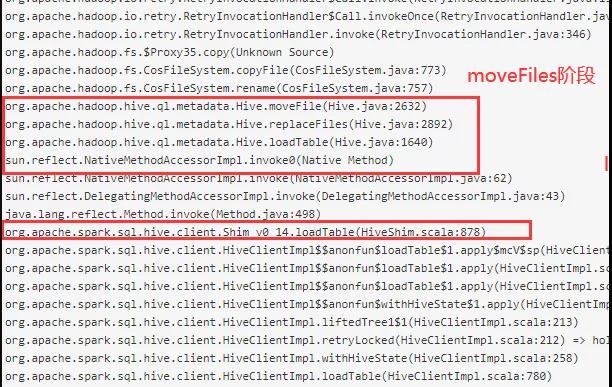
(3)MoveFiles阶段
与前面问题类似,在 moveFiles 阶段也是采用了单线程 for 循环方式来 move 文件。
4. 问题小结
Spark 引擎写海量文件性能瓶颈在Driver端;
在 Driver 的 CommitJob、TrashFiles、MoveFiles 三个阶段执行耗时都比较长;
三个阶段耗时长的原因都是因为单线程循环挨个处理文件;
对象存储的 rename 性能需要拷贝数据,性能较差,导致写海量文件时耗时特别长。
三、优化结果
可以看到社区版本大数据计算引擎在处理对象存储的访问上还在一定的性能问题,主要原因是大多数数据平台都是基于 HDFS 存储,而 HDFS 对文件的 rename 只需要在 namenode 上修改元数据,这个操作是非常快的,不容易碰到性能瓶颈。
而目前数据上云、存算分离是企业降低成本的重要考量,所以我们分别尝试将 commitJob、trashFiles、moveFile 代码修改成多线程并行处理文件,提升对文件写操作性能。
基于同样的基准测试,使用 SparkSQL 分别对 HDFS、对象存储写入 5000 个文件,我们得到了优化后的结果如下图所示:
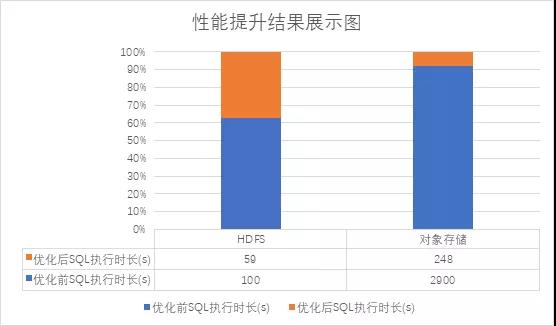
最终写 HDFS 性能提升 41%,写对象存储性能提升 1100% !
四、结语
从上述的分析过程看到,问题的关键是 Spark 引擎某些处理部分的单线程限制造成的。单线程限制其实是比较常见的技术瓶颈。虽然我们在一开始也有猜测这种可能性,但具体限制在哪一部分还需要理清思路,踏实的查看源代码和多次调试。
另外分析中也发现了对象存储自身的限制,其 rename 性能需要拷贝数据,导致写海量文件耗时长,我们也还在持续进行改进。
对存储计算分离应用场景深入优化,提升性能,更好的满足客户对存储计算分离场景下降本增效的需求,是我们腾讯云弹性 MapReduce(EMR) 产品研发团队近期的重要目标,欢迎大家一起交流探讨相关问题。