
BGSAVE:fork一个子进程,子进程负责调用rdbSave,并在保存完成知乎向主进程发送信号,通知保存已经完成。因为是fork的子进程,所以主进程还是可以正常工作,接受客户端的请求
整个流程可以用伪代码表示:
def SAVE(): rdbSave() def BGSAVE(): pid = fork() if pid == 0: # 子进程保存 RDB rdbSave() elif pid > 0: # 父进程继续处理请求,并等待子进程的完成信号 handle_request() else: # pid == -1 # 处理 fork 错误 handle_fork_error()当然,写入之后就是load了。当redis服务重启,就会将存在的dump.rdb文件重新载入到内存中,用于数据恢复,那么redis是怎么做的呢?
额,这一节重点是RDB文件的结构,如果有兴趣,可以自己去看下dump.rdb文件,然后对照一下很容易就明白了。
3. AOFAOF是append only file的缩写,意思是追加到唯一的文件,从上面对RDB的介绍我们知道,RDB的写入是触发式的,等待多少秒或者多少次写入才会持久化到文件中,但是AOF是实时的,它会记录你的每一个命令。
同步到AOF文件的整个过程可以分为三个阶段:
命令传播:redis将执行的命令、参数、参数个数都发送给AOF程序
缓存追加:AOF程序将收到的数据整理成网络协议的格式,然后追加到AOF的内存缓存中
文件写入和保存:AOF缓存中的内容被写入到AOF文件的尾巴,如果设定的AOF保存条件被满足,fsync或者或者fdatasync函数会被调用,将写入的内容真正保存到磁盘中
对于第三点我们需要说明一下,在前面我们说到,RDB是触发式的,AOF是实时的。这里怎么又说也是满足条件了呢?原来redis对于这个条件,有以下的方式:
AOF_FSYNC_NO:不保存。这时候,调用flushAppendOnlyFile函数的时候WRITE都会执行(写入AOF程序的缓存),但SAVE会(写入磁盘)跳过,只有当满足:redis被关闭、AOF功能被关闭、系统要刷新缓存(空间不足等),才会进行SAVE操作。这种方式相当于迫不得已才会进行SAVE,但是很不幸,这三种操作都会引起redis主进程的阻塞
AOF_FSYNC_EVERYSEC:每一秒保存一次。因为SAVE是后台子线程调用的,所有主线程不会阻塞。
AOF_FSYNC_ALWAYS:每执行一个命令保存一次。这个很好理解,但是因为SAVE是redis主进程执行的,所以在SAVE时候主进程阻塞,不再接受客户端的请求
补充:对于第二种的流程可能比较麻烦,用一个图来说明:
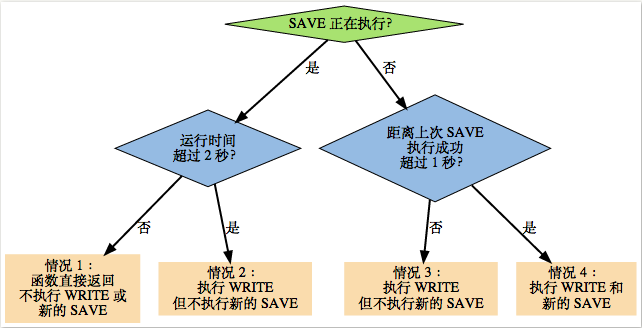
如果仔细看上面的条件,会发现一会SAVE是子线程执行的,一会是主进程执行的,那么怎样从根本上区分呢?
我个人猜测是区分操作的频率,第一种情况是服务都关闭了,主进程肯定会做好善后工作,发现AOF开启了但是没有写入磁盘,于是自己麻溜就做了;第二种情况,因为每秒都需要做,主进程不可能用一个定时器去写入磁盘,这时候用一个子线程就可以圆满完成;第三种情况,因为一个命令基本都是特别小的,所以执行一次操作估计非常非常快,所以主进程再调用子线程造成的上下文切换都显得有点得不偿失了,于是主进程自己搞定。【待验证】
对于上面三种方式来说,最好的应该是第二种,因为阻塞操作会让 Redis 主进程无法持续处理请求,所以一般说来,阻塞操作执行得越少、完成得越快,Redis 的性能就越好。
模式 1 的保存操作只会在AOF 关闭或 Redis 关闭时执行, 或者由操作系统触发, 在一般情况下, 这种模式只需要为写入阻塞, 因此它的写入性能要比后面两种模式要高, 当然, 这种性能的提高是以降低安全性为代价的: 在这种模式下, 如果运行的中途发生停机, 那么丢失数据的数量由操作系统的缓存冲洗策略决定。
模式 2 在性能方面要优于模式 3 , 并且在通常情况下, 这种模式最多丢失不多于 2 秒的数据, 所以它的安全性要高于模式 1 , 这是一种兼顾性能和安全性的保存方案。
模式 3 的安全性是最高的, 但性能也是最差的, 因为服务器必须阻塞直到命令信息被写入并保存到磁盘之后, 才能继续处理请求。
AOF文件的还原