
具体操作步骤:
(a)对于“区域开始的HTML”,可以在已打开的列表首页,单击右键后选择“查看源文件”查找出第一篇文章的标题“高清壁纸”来获得,如(图16)所示,
图16-查看源文件中,第一篇文章的标题
通过观察,不难看出“<ul class="list_left_nr">”为整个列表的开始部分。因此,在“区域开始的HTML”中,应填入“<ul class="list_left_nr">”。
(b)在源文件中,找到最后一篇文章标题“阿奴比斯”,如(图17)所示,
图17-查看源文件中,最后一篇文章的标题
结合列表的开始部分并通过观察可知,第一个“</ul>”为整个列表的结束部分,而其后的从“<ul class=”list_left_bottomw”>”到第二个“</ul>”,则为页面的换页部分。因此,在“区域结束的HTML”中,应填入”</ul>”,意思是到第一个</ul>结束。
(c)经过观察图16和图17的文章标题部分,可以发现,标题的链接地址都是含有“=.html”的。因此,可在“必须包含”中,填入“=.html”。
到这里,“文章网址匹配规则“就设置结束了。填写后,如(图18)所示,
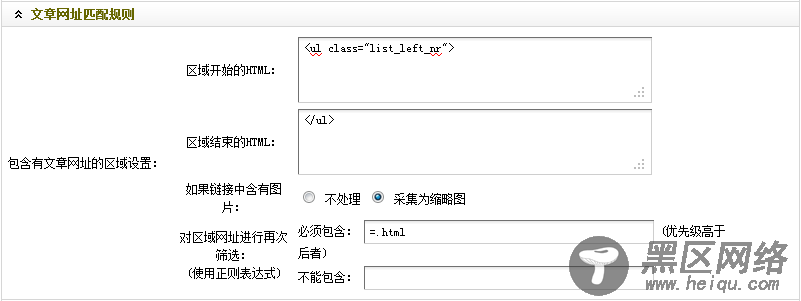
图18-设置后的文章网址匹配规则
通过以上的三个小节,新增采集节点的第一步就已经设置完成了。设置后的最终结果,如(图19)所示,

图19-设置后的新增采集节点:第一步设置基本信息及网址索引页规则
全部完成并检查无误后,单击“保存信息并进入下一步设置“。如果之前设置正确,单击后,将会进入“新增采集节点:测试基本信息及网址索引页规则设置的网址获取规则测试”页面并看到相应的文章列表地址。如(图20)所示,

图20-网址获取规则测试
确定正确无误后,单击“保存信息并进入下一步设置”。否则,请单击“返回上一步进行修改“。
到这里,第一节就结束了。下面进入第二节。。。