
以下以 master 节点为例。登陆实例后,默认用户为 ubuntu,首先需要创建一个 hadoop 用户:
$ sudo useradd -m hadoop -s /bin/bash # 增加 hadoop用户 $ sudo passwd hadoop # 设置密码,需要输入两次 $ sudo adduser hadoop sudo # 为 hadoop 用户增加管理员权限 $ su hadoop # 切换到 hadoop 用户,需要输入密码 $ sudo apt-get update # 更新 apt 源这一步完成之后,终端用户名会变为 hadoop,且 /home 目录下会另外生成一个 hadoop 文件夹。

Hadoop 依赖于 Java 环境,所以接下来需要先安装 JDK,直接从官网下载,这里下的是 Linux x64 版本 jdk-8u231-linux-x64.tar.gz ,用 scp 远程传输到 master 机。注意这里只能传输到 ubuntu 用户下,传到 hadoop 用户下可能会提示权限不足。
$ scp -i xxx.pem jdk-8u231-linux-x64.tar.gz ubuntu@ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com:/home/ubuntu/ # 本地执行该命令本篇假设所有软件都安装在 /usr/lib 目录下:
$ sudo mv /home/ubuntu/jdk-8u231-linux-x64.tar.gz /home/hadoop # 将文件移动到 hadoop 用户下 $ sudo tar -zxf /home/hadoop/jdk-8u231-linux-x64.tar.gz -C /usr/lib/ # 把JDK文件解压到/usr/lib目录下 $ sudo mv /usr/lib/jdk1.8.0_231 /usr/lib/java # 重命名java文件夹 $ vim ~/.bashrc # 配置环境变量,貌似EC2只能使用 vim添加如下内容:
export JAVA_HOME=/usr/lib/java export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH $ source ~/.bashrc # 让配置文件生效 $ java -version # 查看 Java 是否安装成功如果出现以下提示则表示安装成功:
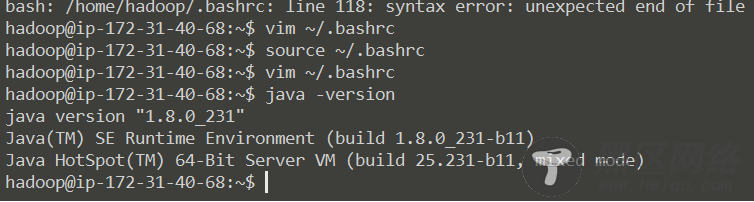
在 master 节点完成上述步骤后,在两个 slave 节点完成同样的步骤 (新增 hadoop 用户、安装 Java 环境)
网络配置这一步是为了便于 Master 和 Slave 节点进行网络通信,在配置前请先确定是以 hadoop 用户登录的。首先修改各个节点的主机名,执行 sudo vim /etc/hostname ,在 master 节点上将 ip-xxx-xx-xx-xx 变更为 Master 。其他节点类似,在 slave01 节点上变更为 Slave01,slave02 节点上为 Slave02。
然后执行 sudo vim /etc/hosts 修改自己所用节点的IP映射,以 master 节点为例,添加红色区域内信息,注意这里的 IP 地址是上文所述的私有 IP:
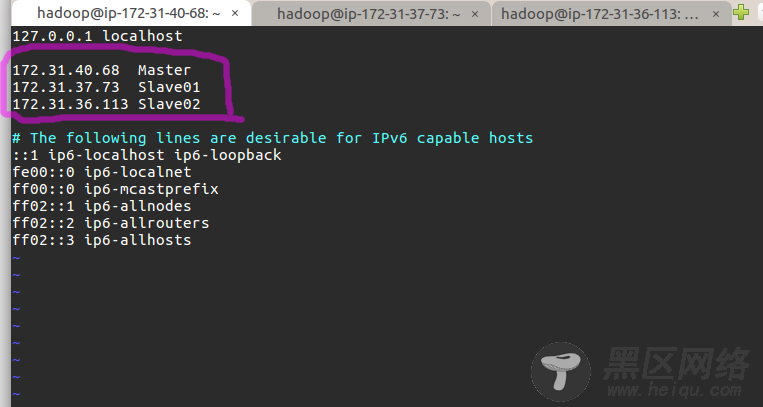
接着在两个 slave 节点的hosts中添加同样的信息。完成后重启一下,在进入 hadoop 用户,能看到机器名的变化 (变成 Master 了):
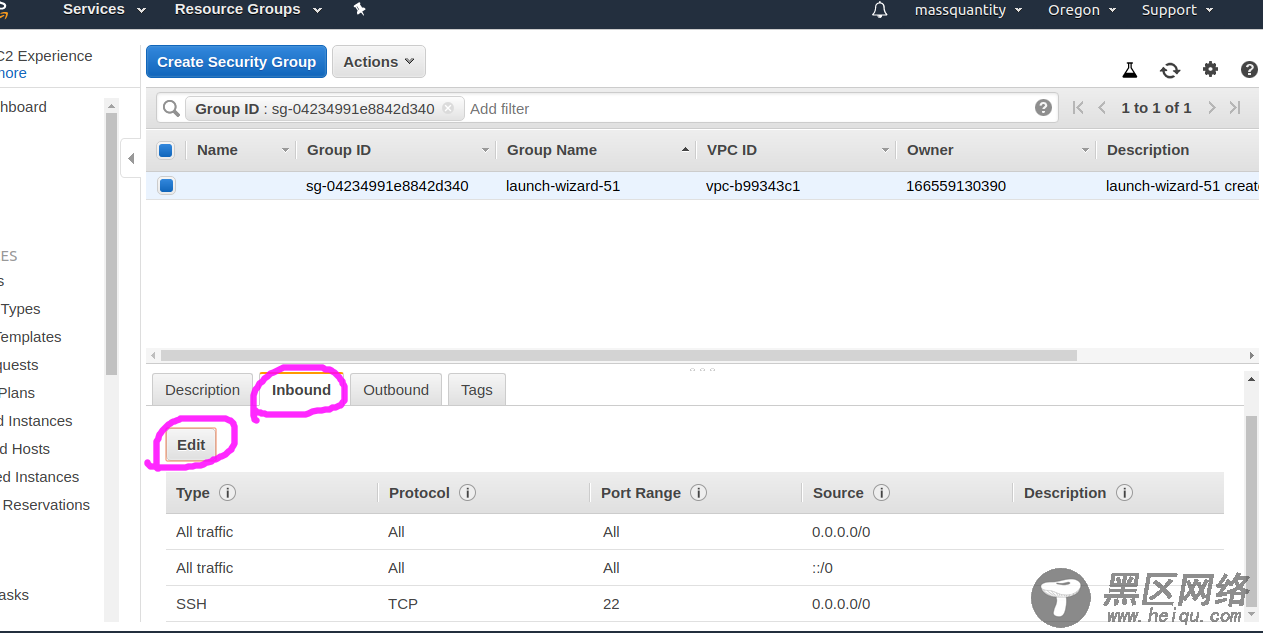
对于 ec2 实例来说,还需要配置安全组 (Security groups),使实例能够互相访问 :
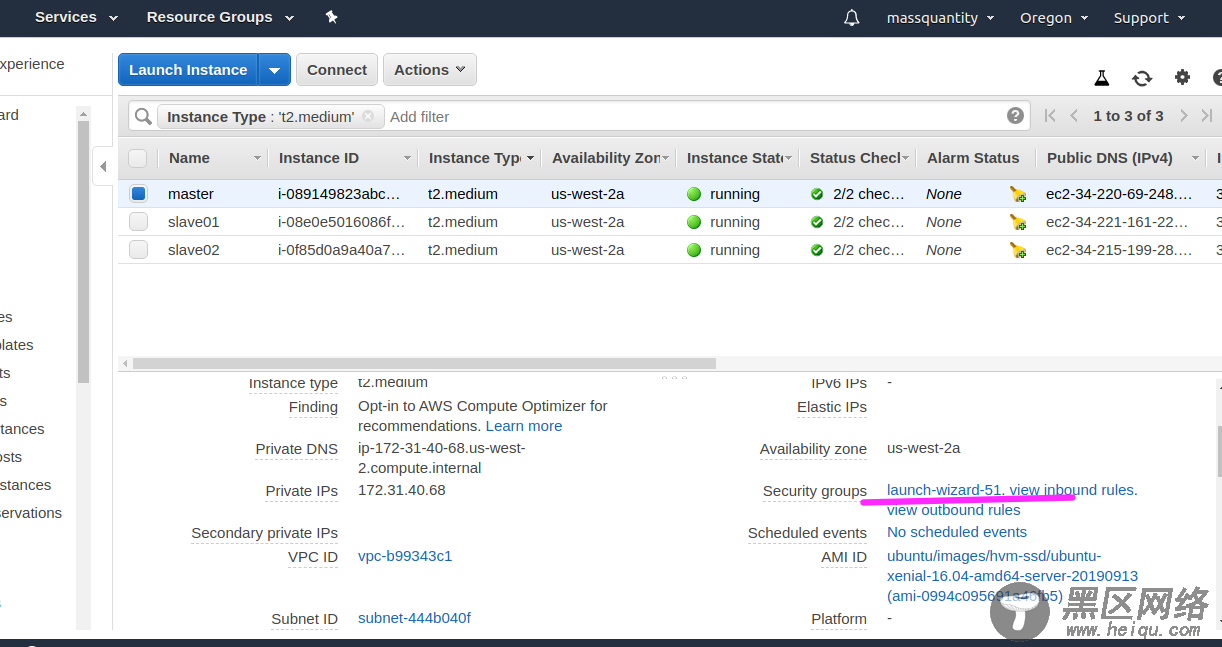
选择划线区域,我因为是同时建立了三台实例,所以安全组都一样,如果不是同时建立的,这可能三台都要配置。
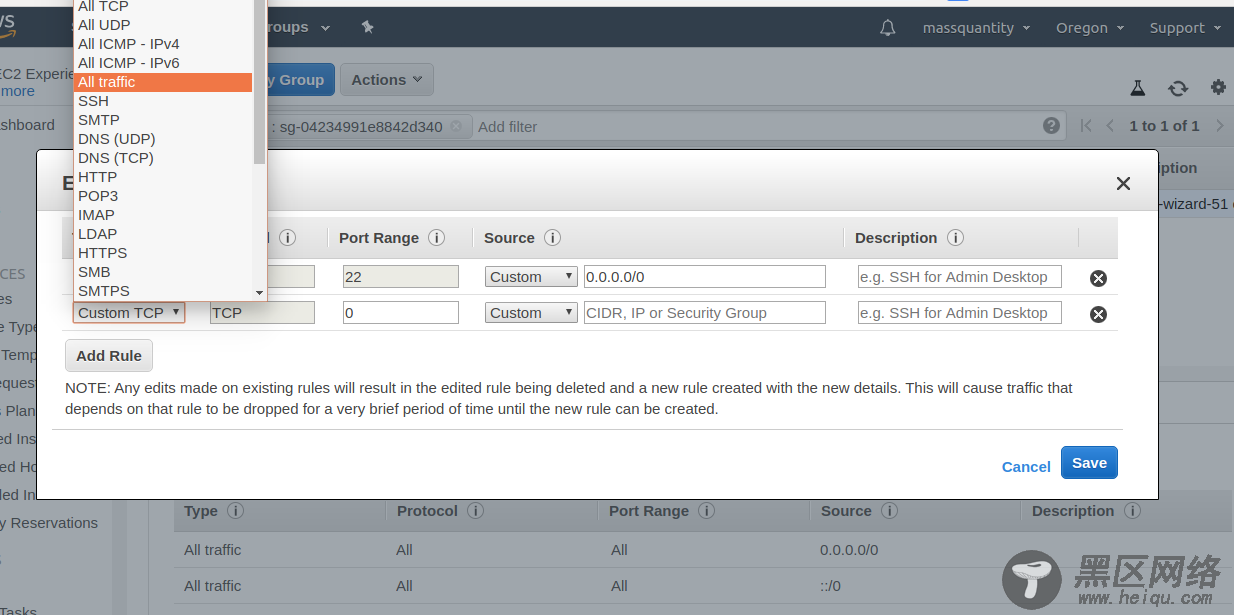
进入后点击 Inbound 再点 Edit ,再点击 Add Rule,选择里面的 All Traffic ,接着保存退出:
三台实例都设置完成后,需要互相 ping 一下测试。如果 ping 不通,后面是不会成功的:
$ ping Master -c 3 # 分别在3台机器上执行这三个命令 $ ping Slave01 -c 3 $ ping Slave02 -c 3
接下来安装 SSH server, SSH 是一种网络协议,用于计算机之间的加密登录。安装完 SSH 后,要让 Master 节点可以无密码 SSH 登陆到各个 Slave 节点上,在Master节点执行:
$ sudo apt-get install openssh-server $ ssh localhost # 使用 ssh 登陆本机,需要输入 yes 和 密码 $ exit # 退出刚才的 ssh localhost, 注意不要退出hadoop用户 $ cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost $ ssh-keygen -t rsa # 利用 ssh-keygen 生成密钥,会有提示,疯狂按回车就行 $ cat ./id_rsa.pub >> ./authorized_keys # 将密钥加入授权 $ scp ~/.ssh/id_rsa.pub Slave01:/home/hadoop/ # 将密钥传到 Slave01 节点 $ scp ~/.ssh/id_rsa.pub Slave02:/home/hadoop/ # 将密钥传到 Slave02 节点