三、添加新的master standby
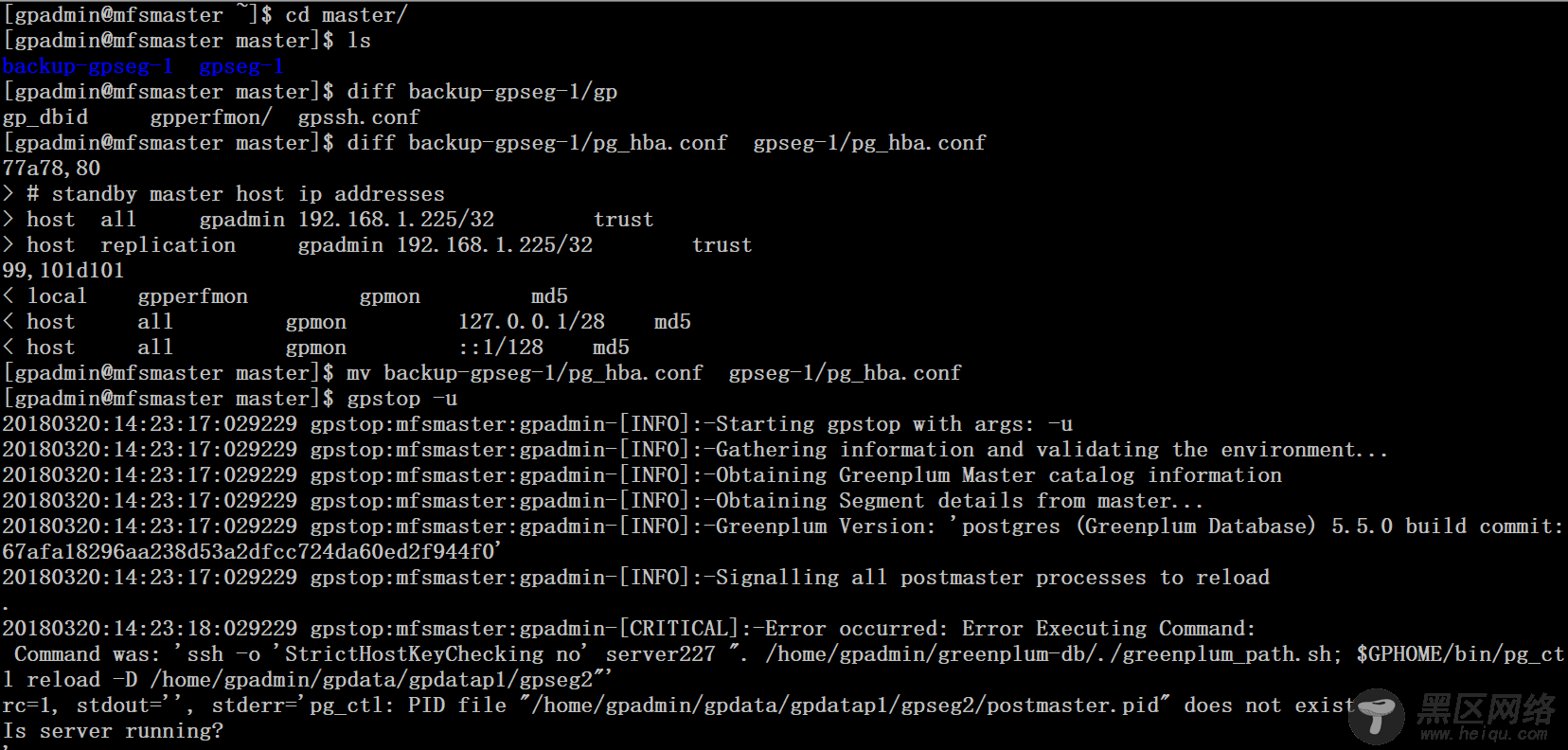
1、 在225服务器上执行gpstart -a命令启动gpdb数据库的时候报错”error: Standby active, this node no more can act as master”。当standby 提升为master的时候,原master服务器从故障中恢复过来,需要以standby的角色加入
2、在原master服务器225上的数据进行备份
$ cd master/
$ ls
gpseg-1
$ mv gpseg-1/ backup-gpseg-1
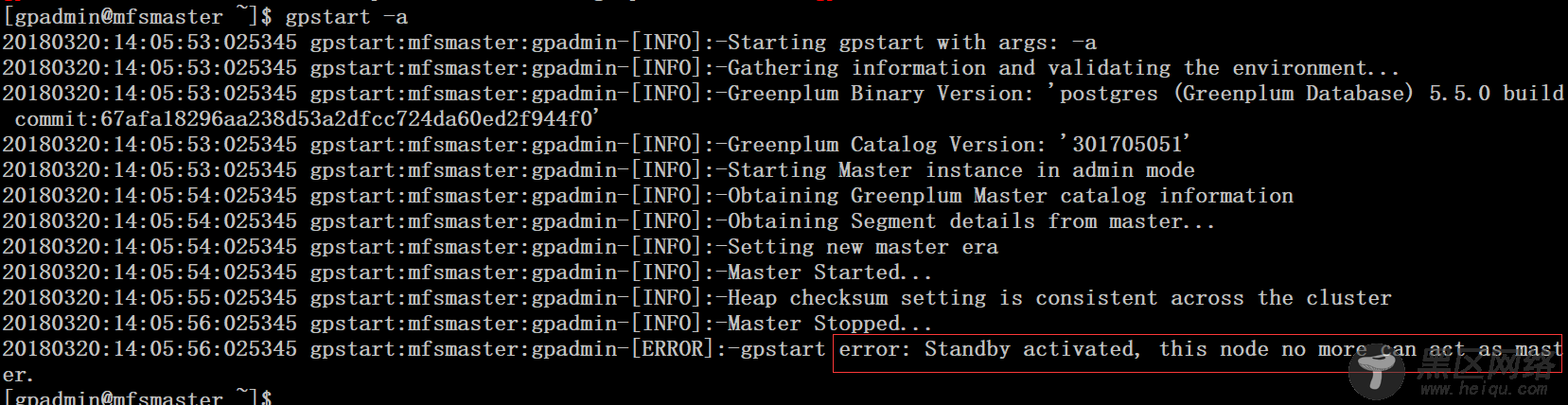
3、在当前master服务器227上进行 gpinitstandby添加225为standby
$ gpinitstandby -s mfsmaster
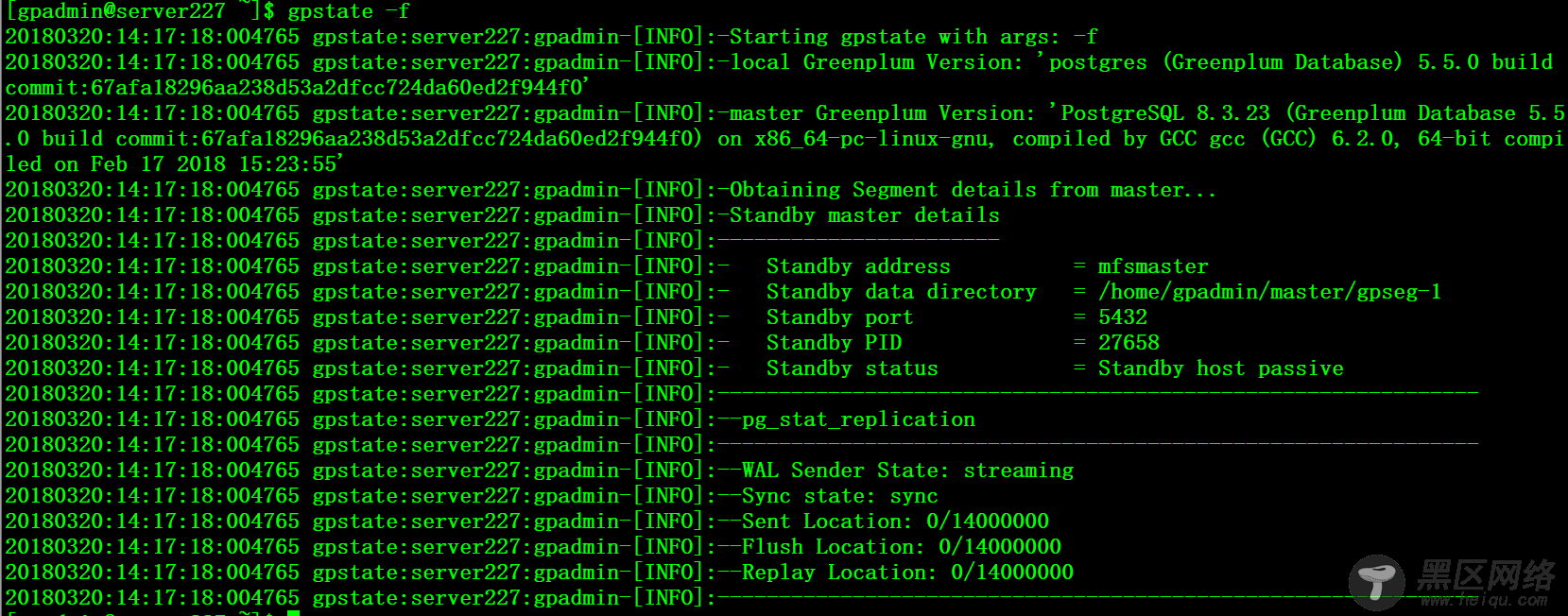
$ gpstate -f
四、primary segment和mirror segment切换
1、首先我们来捋一下当前的数据库环境
Master segment: 192.168.1.227/24 hostname: server227
Stadnby segemnt: 192.168.1.225/24 hostname: mfsmaster
Segment 节点1: 192.168.1.227/24 hostname: server227
Segment 节点2: 192.168.1.17/24 hostname: server17
Segment 节点3: 192.168.1.11/24 hostname: server11
每个segment节点上分别运行一个primary segment和一个mirror segment
2、接着我们采用同样的方式把227服务器上gpadmin用户的所有进行杀掉
$ killall -u gpadmin
3、在225服务器上执行切换master命令
$ gpactivatestandby -d master/gpseg-1/
4、完成切换后使用客户端工具连接查看segment状态,可以看到227服务器上的server227
的primary和mirror节点都已经宕机了。
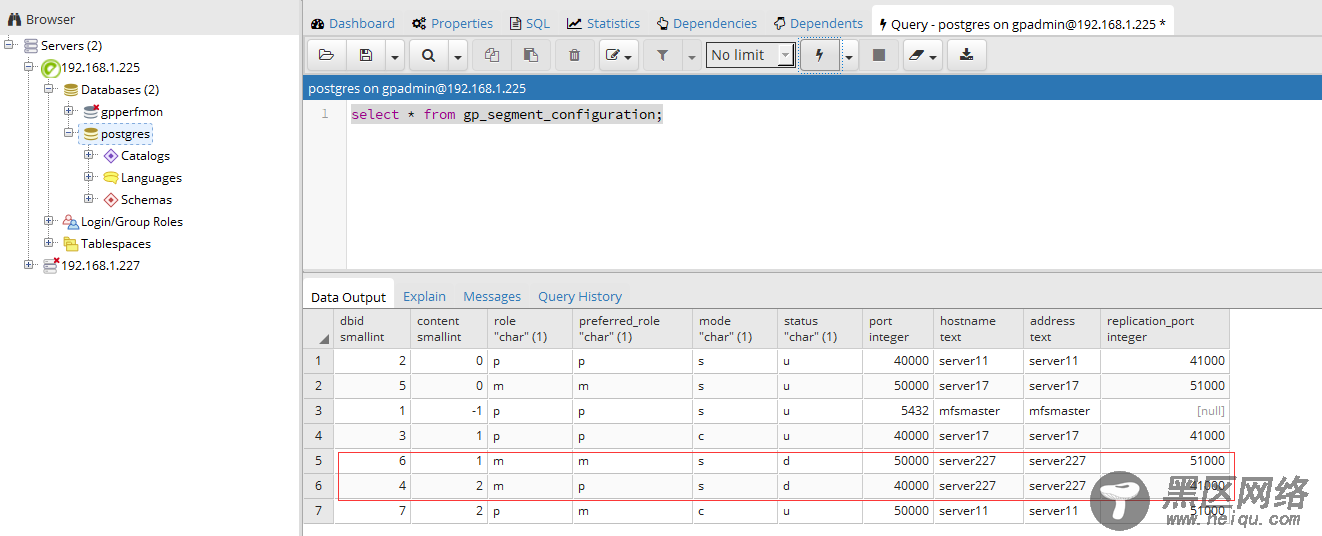
5、这里为了方面查看,我们使用greenplum-cc-web工具来查看集群状态
$ gpcmdr --start hbjy
需要将pg_hba.conf文件还原回去,因为227上所有的segment已经宕掉,执行gpstop -u命令会有报错