
需要注意的是:B*索引中不存在非唯一限制,也就是说非唯一列上也可以创建B*索引,但是在一个非唯一索引中,Oracle会把rowid作为一个额外的列(有一个长度字节)追加到键上,使得键唯一,例如有一个create index index_name on table( x ,y)索引,从概念上说,他就是create unique index index_name on table( x ,y,rowid).在一个唯一索引中,根据你定义的唯一性,Oracle 不会再向索引键增加rowid,在非唯一索引中,你会发现,数据会首先按索引键值排序,然后按rowid升序排序,而在唯一索引中,数据只按着索引键值排序;
三:使用B*树索引检索数据的过程。
针对下图B+tree索引的原理(修改自网络):
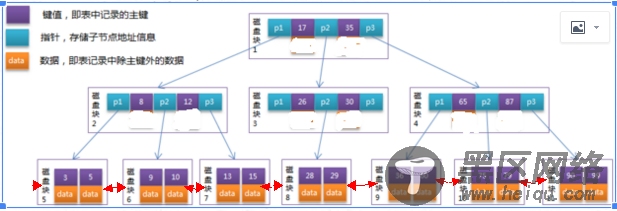
然后针对上图模拟下 where id=29的具体过程:。
首先根据根节点找到磁盘块1,读入内存。【磁盘I/O操作第1次】
比较关键字29在区间(17,35),找到磁盘块1的指针P2。
根据P2指针找到磁盘块3,读入内存。【磁盘I/O操作第2次】
比较关键字29在区间(26,30),找到磁盘块3的指针P2。
根据P2指针找到磁盘块8,读入内存。【磁盘I/O操作第3次】
在磁盘块8中的关键字列表中找到关键字29。
分析上面过程,发现需要3次磁盘I/O操作,和3次内存查找操作。由于内存中的关键字是一个有序表结构,可以利用二分法查找提高效率。而3次磁盘I/O操作是影响整个B-Tree查找效率的决定因素。
四:Oracleb*tree索引的限制
1)在索引列上使用函数。如SUBSTR,DECODE,INSTR等,对索引列进行运算.需要建立函数索引就可以解决了。
例如:表dept,有col_1,col_2,现在对col_1做upper函数索引 如下:
CREATE INDEX index_name ON dept(upper(col_1));
函数索引是基于代价的优化方式-CBO,(在Oracle8及以后的版本,Oracle强列推荐用CBO的方式,而非RBO),所以表必须经过analyze才可以使用,或者使用hints才可以 ;
2)新建的表还没来得及生成统计信息,分析一下就好了,我们知道Oracle优化器是基于统计信息来判断执行计划的,如果统计信息不准确,那么Oracle可能会做出不走索引的执行计划。
3)Oracle优化器cbo是基于cost的成本分析,访问的表过小,使用全表扫描的消耗小于使用索引。
4)使用<>、not in 、not exist,对于这三种情况中大多数情况下认为结果集很大,一般大于5%-15%就不走索引而走全表扫描(FTS)。
5) like "%_" 百分号在前。
6) 单独引用复合索引里非第一位置的索引列,Oracle和mysql一样,btree索引都是最左匹配原则,当你创建组合索引(A,B,C)相当于创建了(A)、 (A,B)、(A,B,C)三个索引;
7)字符型字段为数字时在where条件里不添加引号,这里Oracle内部使用函数做隐士转换,所以可以归结为第一类,使用函数导致索引失效,值得注意的是:VARCHAR2->NUMBER的隐式转换,可以走索引;NUMBER->VARCHAR2的隐式转换,就导致索引失效了。(VARCHAR2->NUMBER不会让索引失效,可以理解成转换为where id = to_number('123')。NUMBER->VARCHAR2会让索引失效,我猜测是转换为where to_number(name) = 123)
8)当变量采用的是times变量,而表的字段采用的是date变量时.或相反情况。
9)索引失效(INVALID),可以考虑重建索引,alter index index_name rebuild online;。
10)B-tree索引 is null不会走,is not null会走;
五:Oracle和mysql的btree索引的区别
其实Oracle和mysql的btree索引结构和原理很相似,只是Oracle叶子节点存储的是键值+rowid,mysql的索引叶子结点存储的内容因存储引擎不同而不同,还有主键索引和二级索引之分如下:
Oracle叶子节点存储的是键值+rowid
MyISAM引擎中leaf node存储的内容:
主键索引 :仅仅存储行指针;
二级索引:仅仅是行指针;
InnoDB引擎中leaf node存储的内容
主键索引 :聚集索引存储完整的数据(整行数据)(类似于Oracle的索引组织表)
二级索引:存储索引列值+主键信息
总结:
索引能提高检索数据的效率,但是索引的建立必须慎重,对每个索引的必要性都应该经过仔细分析,要有建立的依据。因为太多的索引与不充分、不正确的索引对性能都毫无益处:在表上建立的每个索引都会增加存储开销,索引对于插入、删除、更新操作也会增加处理上的开销。另外,过多的复合索引,在有单字段索引的情况下,一般都是没有存在价值的;相反,还会降低数据增加删除时的性能,特别是对频繁更新的表来说,负面影响更大。