传统架构
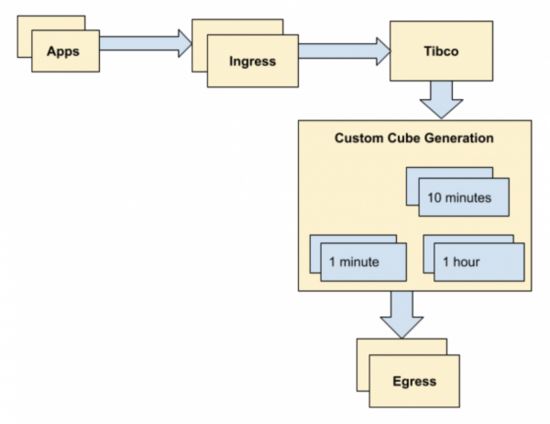
传统架构是多年前设计的,当时整个站点每天生成的事件数量大约为 1000 万次。这在当时是可扩展的,并且在未来几年内也可以进行扩展。
随着时间的推移,传统架构暴露了一些缺点:
多维数据集生成是每个时间间隔的自定义编写代码。生成当前时间的数据通常需要几分钟,这对于实时监控而言是不可接受的。而且这种延迟随着数据量的增加而增加。
随着数据量的增加,自定义多维数据生成的可扩展性随时间的推移效果变得较差。
在维度基数非常高(几十万到几百万种组合)的情况下,生成速度缓慢或无法创建多维数据集。
新架构
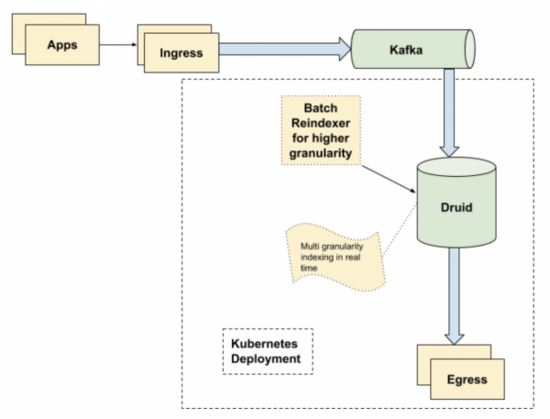
在新的架构中,已删除 Tibco 依赖项,并将 Kafka 用做临时保存信息以供使用的层。Tranquilty 用于使用来自 Kafka 的数据并输入 Druid。
新架构的要点如下:
从时间生成到出口实现的最小端到端延迟(对于非常大的应用程序,最大不超过 10 秒)。
使用 Druid 处理多种粒度的数据,如 1 分钟、1 刻钟、1 小时等。重新索引 1 天间隔的数据。
Kubernetes 部署使我们在升级或维护时,能够在几分钟之内删除集群并重新创建集群。使用 100 个节点执行滚动更新非常容易。
Druid 可有效地处理高基数数据,只要为索引任务提供足够的可扩展性,即使是数以百万计的纬度值,也可以使用 Druid 来处理,而不会产生任何额外的延迟,索引任务可在零停机时间内实现。
(Tibco 是一种用于数据传输的企业消息总线。Tranquilty 是 Druid-io 的一部分,它带了一个将数据流发送到 Druid 的 API。)
事件处理
事件包括系统中发生的事情,这些事情从本质上来讲是零星的。一些应用程序每天会生成一些事件,而其他应用程序在一分钟内会生成数百万个事件。不同类型的事件可根据它们的用途来生成。我们在此背景下讨论监控事件。
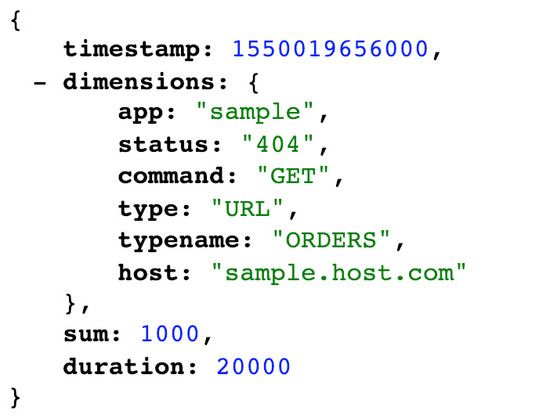
在我们的用例中,数据具有一个固定的维度键(11 维),一个时间戳和两个要计算的度量:计数和延迟。计数是在特定时间戳收集数据时主机发生的事件数量。延迟表示所有事务的延迟总和。跨应用程序的数千个主机可能会生成数以百万计的事件,每个事件可以包含不同的纬度值集。每个应用程序的每个维度的纬度值可以从十到几千不等。